Many of us use Python Selenium to do
functional testing of our websites or web applications. We generally test
against Firefox and Google Chrome browser on the desktop. But, there is also a
lot of people who uses Tor
Browser (from Tor
Project) to browse the internet and access the
web applications.
In this post we will see how can we use the Tor Browser along with Selenium for
our testing.
Setting up the environment
First step is to download and verify, and then extract the Tor Browser
somewhere in your system. Next, download and extract
geckodriver
0.17.0 somewhere in the path. For the current series of Tor Browsers, you will
need this particular version of the geckodriver.
We will use pipenv to create the Python virtualenv
and also to install the dependencies.
The tor-browser-selenium is
Python library required for Tor Browser Selenium tests.
Example code
import unittest
from time import sleep
from tbselenium.tbdriver import TorBrowserDriver
class TestSite(unittest.TestCase):
def setUp(self):
# Point the path to the tor-browser_en-US directory in your system
tbpath = '/home/kdas/.local/tbb/tor-browser_en-US/'
self.driver = TorBrowserDriver(tbpath, tbb_logfile_path='test.log')
self.url = "https://check.torproject.org"
def tearDown(self):
# We want the browser to close at the end of each test.
self.driver.close()
def test_available(self):
self.driver.load_url(self.url)
# Find the element for success
element = self.driver.find_element_by_class_name('on')
self.assertEqual(str.strip(element.text),
"Congratulations. This browser is configured to use Tor.")
sleep(2) # So that we can see the page
if __name__ == '__main__':
unittest.main()
In the above example, we are connecting to the https://check.torproject.org and
making sure that it informs we are connected over Tor. The tbpath variable in
the setUp method contains the path to the Tor Browser in my system.
You can find many other
examples
in the source repository.
Please make sure that you test web application against Tor Browser, having more
applications which can run smoothly on top of the Tor Browser will be a great
help for the community.
PyQt is the Python binding for Qt library. To write Qt5
code, we use PyQt5 module. Like many others, my first introduction to GUI
application development was using PyQt. Back in foss.in 2005 a talk from
Sirtaj introduced me to PyQt, and later fall in love with
it.
I tried to help in a GUI application after 8 years (I think), a lot of things
have changed in between. But, Qt/PyQt still seems to be super helpful when it
comes to ease of development. Qt has one of the best
documentation out there for any Open Source project.
Many students start developing GUI tools by replacing one of the command line
tool they use. Generally the idea is very simple, take some input in the GUI,
and then process it (using a subprocess call) on a button click, and then show
the output. The subprocess call happens over a simple method, means the whole
GUI gets stuck till the function call finishes. We can fix this issue by using
a QThread. In the below example, we will
just write a frontend for git clone command and then will do the same using
QThread.
Setting up project directory
I have used qt creator to create a
simple MainWindow form and saved it as mainwindow.ui in the project
directory. Then, used pipenv to create a virtualenv and also installed the
pyqt5 module. Next, used the pyuic5 command to create a Python file from
UI file.
The code does not have error checks, the subprocess
documentation should give
you enough details about how to add them.
Doing git clone without any thread
The following code creates a temporary directory, and then git clones any given
git repository into that.
#!/usr/bin/python3
import sys
import tempfile
import subprocess
from PyQt5 import QtWidgets
from mainwindow import Ui_MainWindow
class ExampleApp(QtWidgets.QMainWindow, Ui_MainWindow):
def __init__(self, parent=None):
super(ExampleApp, self).__init__(parent)
self.setupUi(self)
# Here we are telling to call git_clone method when
# someone clicks on the pushButton.
self.pushButton.clicked.connect(self.git_clone)
# Here is the actual method which does git clone
def git_clone(self):
git_url = self.lineEdit.text() # Get the git URL
tmpdir = tempfile.mkdtemp() # Creates a temporary directory
cmd = "git clone {0} {1}".format(git_url, tmpdir)
subprocess.check_output(cmd.split()) # Execute the command
self.textEdit.setText(tmpdir) # Show the output to the user
def main():
app = QtWidgets.QApplication(sys.argv)
form = ExampleApp()
form.show()
app.exec_()
if __name__ == '__main__':
main()
Doing git clone with a thread
In the below example we added a new CloneThread class, it has a run method,
which gets called when the thread starts. At the end of the run, we are
emitting a signal to inform the main thread that the git clone operation has
finished.
#!/usr/bin/python3
import sys
import tempfile
import subprocess
from PyQt5 import QtWidgets
from PyQt5.QtCore import QThread, pyqtSignal
from mainwindow import Ui_MainWindow
class CloneThread(QThread):
signal = pyqtSignal('PyQt_PyObject')
def __init__(self):
QThread.__init__(self)
self.git_url = ""
# run method gets called when we start the thread
def run(self):
tmpdir = tempfile.mkdtemp()
cmd = "git clone {0} {1}".format(self.git_url, tmpdir)
subprocess.check_output(cmd.split())
# git clone done, now inform the main thread with the output
self.signal.emit(tmpdir)
class ExampleApp(QtWidgets.QMainWindow, Ui_MainWindow):
def __init__(self, parent=None):
super(ExampleApp, self).__init__(parent)
self.setupUi(self)
self.pushButton.setText("Git clone with Thread")
# Here we are telling to call git_clone method when
# someone clicks on the pushButton.
self.pushButton.clicked.connect(self.git_clone)
self.git_thread = CloneThread() # This is the thread object
# Connect the signal from the thread to the finished method
self.git_thread.signal.connect(self.finished)
def git_clone(self):
self.git_thread.git_url = self.lineEdit.text() # Get the git URL
self.pushButton.setEnabled(False) # Disables the pushButton
self.textEdit.setText("Started git clone operation.") # Updates the UI
self.git_thread.start() # Finally starts the thread
def finished(self, result):
self.textEdit.setText("Cloned at {0}".format(result)) # Show the output to the user
self.pushButton.setEnabled(True) # Enable the pushButton
def main():
app = QtWidgets.QApplication(sys.argv)
form = ExampleApp()
form.show()
app.exec_()
if __name__ == '__main__':
main()
The example looks like the above GIF. You can find the source code
here. You can find a bigger
example in the
journalist_gui
of the SecureDrop project.
In case you missed the news, Fedora 28 is now available as a template in Qubes
OS 4.0. Fedora 26 will end of life on 2018-06-01, means
this is a good time for everyone to upgrade. Use the following command in your
dom0 to install the template. The template is more than 1GB in size, means it
will take some time to download.
$ sudo qubes-dom0-update qubes-template-fedora-28
After installation, remember to start the template, and update, and also
install all the required applications there. Next step would be to use this
template everywhere.
Btw, we do have the latest Python 3.6.5 in Fedora 28 :)
$ python3
Python 3.6.5 (default, Mar 29 2018, 18:20:46)
[GCC 8.0.1 20180317 (Red Hat 8.0.1-0.19)] on linux
Type "help", "copyright", "credits" or "license" for more information.
>>>
* વિનોદ ભટ્ટે ગઇકાલે એટલે કે ૨૩મી મે એ બધાંને બાય-બાય કર્યું અને ગુજરાતી હાસ્યસાહિત્યનો એક યુગ પૂરો થયો એમ કહી શકાય. વિનોદ ભટ્ટ અને બકુલ ત્રિપાઠી અને અશોક દવે – આ ત્રણ મારા માનીતા હાસ્ય લેખકો છે.
વિનોદ ભટ્ટ એક વખત અકસ્માતે મળી ગયા ત્યારે ઓળખી શક્યો નહોતો (તેઓ સેલ્સ ટેક્સ કે પછી એવા કોઇ વિભાગમાં હતા ત્યારે કોઇ નિમંત્રણ આપવા મામાના ઘરે આવેલા). પછી ખબર પડી કે તેઓ વિનોદ ભટ્ટ હતા!
હવે વિકિપીડિયામાં તેમના લેખમાં વધુ માહિતી ઉમેરીને તેમને શ્રદ્ધાંજલિ અર્પવામાં આવશે.
Seymour Papert is credited as saying that tools to support learning should have “high ceilings” and “low floors.” The phrase is meant to suggest that tools should allow learners to do complex and intellectually sophisticated things but should also be easy to begin using quickly. Mitchel Resnick extended the metaphor to argue that learning toolkits should also have “wide walls” in that they should appeal to diverse groups of learners and allow for a broad variety of creative outcomes. In a new paper, Benjamin Mako Hill and I attempted to provide the first empirical test of Resnick’s wide walls theory. Using a natural experiment in the Scratch online community, we found causal evidence that “widening walls” can, as Resnick suggested, increase both engagement and learning.
Over the last ten years, the “wide walls” design principle has been widely cited in the design of new systems. For example, Resnick and his collaborators relied heavily on the principle in the design of the Scratch programming language. Scratch allows young learners to produce not only games, but also interactive art, music videos, greetings card, stories, and much more. As part of that team, I was guided by “wide walls” principle when I designed and implemented the Scratch cloud variables system in 2011-2012.
While designing the system, I hoped to “widen walls” by supporting a broader range of ways to use variables and data structures in Scratch. Scratch cloud variables extend the affordances of the normal Scratch variable by adding persistence and shared-ness. A simple example of something possible with cloud variables, but not without them, is a global high-score leaderboard in a game (example code is below). After the system was launched, I saw many young Scratch users using the system to engage with data structures in new and incredibly creative ways.
Example of Scratch code that uses a cloud variable to keep track of high-scores among all players of a game.
Although these examples reflected powerful anecdotal evidence, I was also interested in using quantitative data to reflect the causal effect of the system. Understanding the causal effect of a new design in real world settings is a major challenge. To do so, we took advantage of a “natural experiment” and some clever techniques from econometrics to measure how learners’ behavior changed when they were given access to a wider design space.
Understanding the design of our study requires understanding a little bit about how access to the Scratch cloud variable system is granted. Although the system has been accessible to Scratch users since 2013, new Scratch users do not get access immediately. They are granted access only after a certain amount of time and activity on the website (the specific criteria are not public). Our “experiment” involved a sudden change in policy that altered the criteria for who gets access to the cloud variable feature. Through no act of their own, more than 14,000 users were given access to feature, literally overnight. We looked at these Scratch users immediately before and after the policy change to estimate the effect of access to the broader design space that cloud variables afforded.
We found that use of data-related features was, as predicted, increased by both access to and use of cloud variables. We also found that this increase was not only an effect of projects that use cloud variables themselves. In other words, learners with access to cloud variables—and especially those who had used it—were more likely to use “plain-old” data-structures in their projects as well.
The graph below visualizes the results of one of the statistical models in our paper and suggests that we would expect that 33% of projects by a prototypical “average” Scratch user would use data structures if the user in question had never used used cloud variables but that we would expect that 60% of projects by a similar user would if they had used the system.
Model-predicted probability that a project made by a prototypical Scratch user will contain data structures (w/o counting projects with cloud variables)
It is important to note that the estimated effective above is a “local average effect” among people who used the system because they were granted access by the sudden change in policy (this is a subtle but important point that we explain this in some depth in the paper). Although we urge care and skepticism in interpreting our numbers, we believe our results are encouraging evidence in support of the “wide walls” design principle.
Of course, our work is not without important limitations. Critically, we also found that rate of adoption of cloud variables was very low. Although it is hard to pinpoint the exact reason for this from the data we observed, it has been suggested that widening walls may have a potential negative side-effect of making it harder for learners to imagine what the new creative possibilities might be in the absence of targeted support and scaffolding. Also important to remember is that our study measures “wide walls” in a specific way in a specific context and that it is hard to know how well our findings will generalize to other contexts and communities. We discuss these caveats, as well as our methods, models, and theoretical background in detail in our paper which now available for download as an open-access piece from the ACM digital library.
This blog post, and the open access paper that it describes, is a collaborative project with Benjamin Mako Hill. Financial support came from the eScience Institute and the Department of Communication at the University of Washington. Quantitative analyses for this project were completed using the Hyak high performance computing cluster at the University of Washington.
Last week, I had an interesting meeting with Panjabi Wikimedian community and CIS-A2K team.
Panjabi wikimedia community is small in count. But each of them are contributing with their best. Many of them doing 100-days-of-wiki, personal wiki edithathon for 100 days. Few of them do in in multiple sites and many times a year.
Their interest on contribution and passion on their language is awesome.
Interacted on wikisource, wiktionary and wikipedia. Shared many ideas to improve their workflow. They are looking for many tools to automate their tasks. Those tools will be useful for all wiki communities.
Then, had some great discussions with CIS-A2K team. We spoke about many interesting project ideas.
Listing them all the ideas here.
1. List down the Top 10 tricks/hacks/must know on any wikisource project
2. Make simple tutorials on how to start contributing to wiki, in all possible languages. Still we dont have an ebook or easy starter guide in Tamil. There may be video tutorials. curate them and show them in better way to find them easily.
3. Telegram bot to proofread wikisource contents. Get a page from wikisource. split it into lines, then words. Show a word and OCRed content in a telegrambot. User should verify or type the correct spelling in telegram itself. Submit the changes to wikisource. Thus, we can make the collaborated proofreading easily.
4. Explore how to use flickr for helping photographers to donate their photos for commons. Flickr is easy for them to upload and showcase. From there, we should move the photos to commons. Few tools are already available. Explore them and train them for photographers.
5. We should celebrate the volunteers who contribute to wiki. By events, news announcements, interviews etc. CIS may explore this.
6. Web application for OCR4WikiSource
7. Make a web application to record audio and upload to commons and add in wiktionary words. explore Lingua-Libre for web app.
8. Make a mobile application to record audio and upload to commons and add in wiktionary words.
9. CIS may ask the language based organizations to give their works/tools on public licenses.
10. A one/two day meeting/conference to connect various language technologies. Each team can demonstrate the tools they are working on. others can learn and use them for their languages. CIS may organize this soon.
11. Building spell checkers for Tamil. Learn how other other languages are doing. Odia seems to have good spell checker. Explore that.
12. For iOS, there is no commons app to upload photos. It was there sometime ago. Fix the iOS commons app and rerelease it again.
13. Build Maps with local languages with OSM.
14. One/Two day training on wiki tech. like gadgets, tools, toolserver, API, etc
15. Tweet marketing to promote the ebooks released in wikisource projects. Measure the downloads.
16. CIS may talk with amazon to release the ebooks from wikisource for free always at amazon.
17. Explore Valmigi project of malayalam, chikubuku of kannada – for their ebooks.
19. Explore paid works for wikisource proofreading.
20. Blog on how ta wikisource for 2000 ebooks from TN government in public domain license. Send to CIS. They may try to do the same for other languages.
21. ASI website has info about all monuments. Scrap them all and add in wiki.
22. Scrap details from tourism sites and add in wiki.
23. Kannada archeology site has tons of images but with 3 seals added in all images. scrap them, remove seal and add to commons.
24. Tool to audit wiki sites. like new users, edits, measurements, KPIs, reports etc.
25. Discuss with wiki writers and help them to automate their tasks. Build new tools to help them. train existing tools.
26. Get existing photos from many photographers. Get license doc. Add in OTRS. Have a team to upload the photos to commons.
27. Find the pages that don’t have images. Search in commons and add 1 image automatically.
28. Infobox in wiki pages may have 1 image. Check for the same page in other languages.. get the image from infobox and use it in missing pages.
29. Tito showed a broken JS script. Explore it and fix it.
ગઇકાલે સહ કુટુંબ 102 નોટ આઉટ માણવામાં આવ્યું. 3ડી ન હોય એવી ફિલ્મો જોવાનું વધતું જાય છે એ સારી વાત છે. ચલ મન જીતવા જઇએ પછી લાંબા વિરામ પછી સરસ બ્રેક મળ્યો.
ફિલ્મની આડઅસર રૂપે સૌમ્ય જોશી વિશે ગુજરાતી વિકિપીડિયામાં લેખ અનુવાદ કરી રહ્યો છું.
A few weeks back, we released the 2.5.0-rc1 version of Apache Ivy. Apache Ivy is a dependency management build tool, which usually is a used in combination with Apache Ant. The download is available on the project download page
This release is significant since the last release of Apache Ivy was way back in December 2014. So it's more than 3 years since the last official years. During these past few years, the project development stalled for a while. I use Apache Ivy in some of our projects and have been pretty happy with the tool. It's never a good sign to see one of your heavily used tools to be no longer under development or even have bug fixes. So a year or so back, I decided to contribute some bug fixes to the project. Over time, the project management committee invited me to be part of the team.
We decided that the first obvious, immediate goal would be to revive the project and do a formal release with bug fixes. This 2.5.0-rc1 is the result of that effort which started almost a year back. A lot of changes have gone into this release and also a good number of enhancements have made it into this release. This release has been a result of contributions from various different members from the community. The complete list of release notes is available here
We intentionally named this release 2.5.0-rc1 (release candidate) since it's been a while we have done an official release and also given the nature of changes. Please give this release a try and let us know how it goes. Depending on the feedback, we will either release 2.5.0 or 2.5.0-rc2. As usual, some of us from the development team keep an active watch in the ivy user mailing list. So if you have any feedback or questions, please do drop a mail to us, there.
Now coming to one of the enhancements in this release - there's been more than one. One of the issues I personally had was if the repository, backing a dependency resolver configured for Ivy, had some connectivity issues, the build would just hang. This was due to the inability to specify proper timeouts for communicating with these repositories through the resolver. As of this release, Ivy now allows you to configure timeouts for resolvers. This is done through the use of (the new) timeout-constraints element in your Ivy settings file. More details about it are here. Imagine you have a url resolver which points to some URL. The URL resolver would typically look something like:
The value for the name attribute can be anything of your choice. The value for connectionTimeout attribute is represented as a timeout in milli seconds. In the above example, we configure the "timeout-1" timeout-constraint to be of 1 minute. You can even specify a readTimeout which too is in milli seconds. More about this element can be found in the documentation.
As you might notice, we have just defined a timeout-constraint here but haven't yet instructed Ivy to use this constraint for some resolver. We do that in the next step, where we set the "timeoutConstraint" attribute on the URL resolver that we had seen before:
Notice that the value of "timeoutConstraint" attribute now points to "timeout-1" which we defined to have a 1 minute connection timeout. With this, when this URL resolver gets chosen by Ivy for dependency resolution, this connection timeout will be enforced and if the connections fails to be established within this timeout, then an exception gets thrown instead of the build hanging forever.
Although the example uses a URL resolver to setup the timeout constraint, this feature is available for all resolvers that are shipped out of the box by Ivy. So you can even use it with the ibiblio resolver (which communicates with Maven central) too.
Like I noted earlier, please do give this release a try and let us know how it goes.
Because of this, we can not do parallel conversion. Few full text books took 4-5 hours for conversion. Because of this, we could not make it as a web application for public use.
Mohan
Mohan helped to make the Tamil TTS Script simpler to process multiple
conversion simultaneously.
now, we need to convert this as a web application, so that anyone can
use it easily.
The requirements are below.
1. user registration with gmail
2. user should upload a tamil text file
3. once it is converted, user should receive an email with the link to
the audio file
4. we can keep the audio files for 1 week
5. REPT API support with authentication
6. A queue system
All these will be released in GPL.
If you are interested in doing this, reply here or write to me.
In one of the projects I have been involved in, we use yavijava (which is a fork of vijava) library to interact with vCenter which hosts our VMs. vCenter exposes various APIs through their webservice endpoints which are invoked through HTTP(s). The yavijava library has necessary hooks which allows developers to use a HTTP client library of their choice on the client side to handle invocations to the vCenter.
In our integration, we plugged in the Apache HTTP client library, so that the yavijava invocations internally end up using this HTTP library for interaction. Things mostly worked fine and we were able to invoke the vCenter APIs. I say mostly, because every once in a while we kept seeing exceptions like:
InvalidLogin : Cannot complete login due to an incorrect user name or password.
This was puzzling since we were absolutely sure that the user name and password we use to interact with the vCenter was correct. Especially since all of the previous calls were going through fine, before we started seeing these exceptions.
The exception stacktrace didn't include anything more useful and neither did any other logs. So the only option that I was left with was to go look into the vCenter (server side) event logs to see if I can find something. Luckily, I had access to a setup which had a vSphere client, which I then used to connect to the vCenter. The vSphere client allows you to view the event logs that were generated on the vCenter.
Taking a look at the logs, showed something interesting and useful. Every time, we had run into this "incorrect user name or password" exception on the client side, there was a corresponding event log on the vCenter server side at INFO level which stated "user cannot logon since user is already logged on". That event log was a good enough hint to give an idea of what might be happening.
Based on that hint, the theory I could form was, somehow for an incoming (login) request, vCenter server side notices something on the request which gives it an impression that the user is already logged in. Given my background with Java EE technologies, the immediate obvious thing that came to mind was that the request was being attached with a "Cookie" which the server side uses to associate requests against a particular session. Since I had access to the client side code which was issuing this login request, I was absolutely sure that the request did not have any explicitly set Cookie header. So that raised the question, who/where the cookie was being associated with the request. The only place that can happen, if it's not part of the request we issued, is within the HTTP client library. Reading up the documentation of Apache HTTP client library confirmed the theory that the HTTP client was automagically associating a (previously generated) Cookie against the request.
More specifically, the HTTP client library uses pooled connections. When a request is made, one of the pooled connections (if any) gets used. What was happening in this particular case was that, a previous login would pick up connection C1 and the login would succeed. The response returned from vCenter for that login request would include a Cookie set in the response header. The Apache HTTP client library was then keeping track of this Cookie against the connection that was used. Now when a subsequent login request arrived, if the same pooled connection C1 gets used for this request, then the HTTP client library was attaching the Cookie that it kept track against this connection C1, to this new request. As a result, vCenter server side ends up seeing that the incoming login request has a Cookie associated with it, which says that there's already a logged in session for that request. Hence, that INFO message in the event logs of vCenter. Of course, the error returned isn't that informative and in fact a bit misleading since it says the username/password is incorrect.
Now that we know what's going on, the solution was pretty straightforward. Apache HTTP client library allows you to configure Cookie policy management. Since in our case, we wanted to handle setting the Cookie explicitly on the request, we decided to go with the "ignoreCookies" policy which can be configured on the HTTP client. More about this can be found in the HTTP client library documentation (see the "Manual Handling of Cookies" section). Once we did this change, we no longer saw this exception anymore.
There isn't much information about this issue anywhere that I could find. The closest I could find was this forum thread https://sourceforge.net/p/vijava/discussion/826592/thread/91550e2a/. It didn't have a conclusive solution, but it does appear that it's the same issue that the user there was running into (almost 7 years back!)
Astute users might have noticed that the GNOME Terminal binary distributed by Fedora has separate menu items for opening new tabs and windows, while the vanilla version available from GNOME doesn’t.
I am happy to say that since version 3.28 GNOME Terminal has regained the ability to have separate menu items as a compile time option. The gnome-terminal-server binary needs to be built with the DISUNIFY_NEW_TERMINAL_SECTION pre-processor macro defined. Here’s one way to do so.
SecureDrop will take part in PyCon
US development sprints (from 14th to 17th May). This
will be first time for the SecureDrop project to present in the sprints.
If you never heard of the project before, SecureDrop is an open source
whistleblower submission system that media organizations can install to
securely accept documents from anonymous sources. Currently, dozens of news
organizations including The Washington Post, The New York Times, The Associated
Press, USA Today, and more, use SecureDrop to preserve the anonymous tipline in
an era of mass surveillance. SecureDrop is installed on-premises in the news
organizations, and journalists and source both use a web application to
interact with the system. It was originally coded by the late Aaron Swartz and
is now managed by Freedom of the Press Foundation.
How to prepare for the sprints
The source code of the project is hosted on
Github.
The web applications, administration CLI tool, and a small Qt-based GUI are all
written in Python. We use Ansible heavily for the orchestration. You can setup
the development environment using Docker. This
section
of the documentation is a good place to start.
A good idea would be to create the initial Docker images for the development
before the sprints. We have marked many issues for PyCon Sprints and also there
are many documentation issues.
Another good place to look is the tests directorty. We use pytest for most of
our test cases. We also have Selenium based functional tests.
Where to find the team?
Gitter is our primary
communication platform. During the sprint days, we will in the same room of the
CPython development (as I will be working on both).
So, if you are in PyCon sprints, please visit us to know more and maybe, start
contributing to the project while in sprints.
[This post was drafted on the day Fedora 27 released, about half a year ago, but was not published. The issue bit me again with Fedora 28, so documenting it for referring next time.]
With fedup and subsequently dnf improving the upgrade experience of Fedora for power users, last few system upgrades have been smooth, quiet, even unnoticeable. That actually speaks volumes of the maturity and user friendliness achieved by these tools.
Upgrading from Fedora 25 to 26 was so event-less and smooth (btw: I have installed and used every version of Fedora from its inception and the default wallpaper of Fedora 26 was the most elegant of them all!).
With that, on the release day I set out to upgrade the main workstation from Fedora 26 to 27 using dnf system-upgrade as documented. Before downloading the packages, dnf warned that upgrade cannot be done because of package dependency issues with grub2-efi-modules and grub2-tools.
Things go wrong!
I simply removed both the offending packages and their dependencies (assuming were probably installed for the grub2-breeze-theme dependency, but grub2-tools actually provides grub2-mkconfig) and proceeded with dnf upgrade --refresh and dnf system-upgrade download --refresh --releasever=27. If you are attempting this, don’t remove the grub2 packages yet, but read on!
Once the download and check is completed, running dnf system-upgrade reboot will cause the system reboot to upgrade target and actual upgrade happen.
Except, I was greeted with EFI MOK (Machine Owner Key) screen on reboot. Now that the grub2 bootloader is broken thanks to the removal of grub2-efi-modules and other related packages, a recovery must be attempted.
Rescue
It is important to have a (possibly EUFI enabled) live media where you can boot from. Boot into the live media and try to reinstall grub. Once booted in, mount the root filesystem under /mnt/sysimage, and EFI boot partition at /mnt/sysimage/boot/efi. Then chroot /mnt/sysimage and try to reinstall grub2-efi-x64 and shim packages. If there’s no network connectivity, don’t despair, nmcli is to your rescue. Connect to wifi using nmcli device wifi connect <ssid> password <wifi_password>. Generate the boot configuration using grub2-mkconfig -o /boot/efi/EFI/fedora/grub.cfg followed by actual install grub2-install --target=x86_64-efi /dev/sdX (the –target option ensures correct host installation even if the live media is booted via legacy BIOS). You may now reboot and proceed with the upgrade.
But this again failed at the upgrade stage because of grub package clash that dnf warned earlier about.
Solution
Once booted into old installation, take a backup of the /boot/ directory, remove the conflicting grub related packages, and copy over the backed up /boot/ directory contents, especially /boot/efi/EFI/fedora/grubx64.efi. Now rebooting (using dnf system-upgrade reboot) had the grub contents intact and the upgrade worked smoothly.
For more details on the package conflict issue, follow this bug.
દર વર્ષની જેમ પણ આ વખતે “કેરીનો છૂંદો” બનાવવાની પ્રક્રિયાનો આરંભ થઇ ગયો છે. મને યાદ છે કે પહેલાં રાજાપુરી કેરીઓ ઘરે લાવીને જાતે છીણીને છૂંદો બનાવાતો હતો. હવે, છીણ બજારમાં તૈયાર મળે છે એટલે ઝંઝટ ઓછી. તો પણ, દરરોજ તડકામાં છૂંદો મૂકવા અને લેવા જવાનું તો હોય છે. મૂકવા જવાનું તો ઠીક, લેવા જવાનું યાદ આવે એ માટે ખાસ એલાર્મ મૂકવામાં આવે છે. ગયા વર્ષે ધાબા પરથી છૂંદો લાવવાનું ભૂલી ગયા હતા ત્યારે ૧.૩૦ વાગે રાત્રે યાદ આવ્યું અને અમારે જવું પડ્યું હતું. ખતરો એ કે રાત્રે કોઇ ઉંદર કે પક્ષી તેને બગાડી નાખે, તેમજ ઠંડીમાં છૂંદોની ગુણવત્તા પર અસર પડી શકે.
છૂંદો એ અમારી કેરી લાલસા છેક દિવાળી સુધી પૂરી કરે છે, એટલે છૂંદો અત્યંત મહત્વનો છે!
I spent the last seven days attending Libre Graphics Meeting in sunny and beautiful Seville. This was my second LGM, the first being six years ago in Vienna, so it was refreshing to be back. I stayed in one of the GIMP apartments near the Alameda de Hércules garden square. Being right in the middle of the city meant that everything of interest was either within walking distance or a short bus ride away.
Unlike other conferences that I have been to, LGM 2018 started at six o’clock in the evening. That was good because one didn’t have to worry about waking up in time not to miss the opening keynote; and you haven’t attended LGM if you haven’t been to the State of Libre Graphics. Other than that I went to Øyvind’s presentation on colour; saw Nara describe her last ten years with Estúdio Gunga; and listened to Dave Crossland and Nathan Willis talk about fonts. There was a lot of live coding based music and algorave going on this year. My favourite was Neil C. Smith’s performance using Praxis LIVE.
All said and done, the highlight of this LGM had to be the GIMP 2.10.0 release at the beginning of the conference. GEGL 0.4.0 was also rolled out to celebrate the occasion. Much happiness and rejoicing ensued.
I spent my time at LGM alternating between delicious tapas, strolling down the narrow and colourful alleys of Seville, sight-seeing, and hacking on GEGL. I started sketching out a proper codec API for GeglBuffer modelled on GdkPixbuf, and continued to performancetune babl, but those are topics for later blog posts.
Four years ago, I migrated this blog from WordPress to Jekyll, with the intention of using whatever format I want to use inside Emacs… Subsequently, my posting rate dropped drastically to just 13 posts in 4 years!
I don’t think that was a coincidence. Tools matter.
I believe the speed and ease of writing dropped drastically. Even simple steps like using photos in a post meant using a separate tool such as Finder.app (on macOS) or command-line to move it to the right directory and then linking to it from the main post. In WordPress, that’s one drag-and-drop and done.
Similarly, no comments was demotivating as well. While there tends to be more nitpicking these days, I would still like to benefit from the wisdom of the crowds.
So now I have migrated back to WordPress. Let’s see how this goes.
* વેકેશન શરૂ થઇ ગયું છે, જોકે મારું વેકેશન તો પૂરું પણ થઇ ગયું છે. વેકેશનમાં કવિનના એક ક્લાસ બંધ કરાવવામાં આવ્યા છે અને એક બીજા ક્લાસ શરૂ કરવાનો પ્લાન છે, તો પણ તેને રમવા-રખડવાનો પૂરતો સમય મળે એનું ધ્યાન રાખેલું છે. જોકે, વેકેશનમાં સૌથી મોટો ત્રાસ નવરા લોકોનો છે, જે છોકરાઓને સોસાયટીના ગ્રાઉન્ડમાં રમવા દેતા નથી. સવારે-બપોરે-સાંજે ત્રણેય સમયે તેઓ કંઇને કંઇ વાંધા-વચકા કાઢવા માટે તૈયાર જ હોય છે. મને થાય છે કે આવા નવરાઓ કેમ વિકિપીડિયા એડિટ કરતા નથી કે કેમ સાયકલ ચલાવતા નથી? શા માટે દોડવાનું શરૂ કરતા નથી કે શા માટે નજીકના પુસ્તકાલયો મુલાકાત લેતા નથી?
கண்ணதாசன், வாலி, வைரமுத்து என்னும் தமிழ்த் திரைப்படப் பாடலாசிரியர்கள் வரிசையில், மேற்சொன்னவர்களுக்கு அடுத்த இடம் கொண்டவர் திரு நா முத்துக்குமார் அவர்கள். "ஒவ்வொரு பூக்களுமே" பாடலுக்கு இந்திய அரசின் விருது கிடைத்த போது, இவருக்கு இன்னும் கிடைக்கவில்லையே என்று வருந்தினேன். இரண்டு ஆண்டுகள் தொடர்ந்து வாங்கினார் பின்னாளில். இதனைப் பாராட்டி வெண்பாவெல்லாம் எழுதினேன் எனது முகநூலில். என்றாவது ஒரு நாள் நேரில் பார்த்தால் காட்டலாம் என்று இருந்தேன்.
இவர் பல இசையமைப்பாளர்களுடன் பணியாற்றி இருந்தாலும், யுவன்சங்கர்ராஜா உடன் பணியாற்றிய பாடல்கள், அக்காலத்தைய இளைஞர்கள் மத்தியில் மிகுந்த புகழ் பெற்றவை.
இயக்குநர் செல்வராகவன் திரைக்கதையில் ஒரு பொது அம்சம்: ஒரு உதவாக்கரை நாயகன் இருப்பான், வீட்டில் உட்பட யாரும் மதிக்க மாட்டார்கள், எங்கிருந்தோ தேவதை போல ஒரு பெண் வருவாள், நாயகன் அவளுக்காகத் திருந்தி முன்னேறுவான். "யாரடி நீ மோகினி" படத்திலும் இதே கதை அமைப்பு உண்டு. அப்போது நாயகன், நாயகியை முதல் முறை, கண்டதும் காதல் கொண்டதும், பின்னணியில் ஒலிக்கும் பாடல், நாமு வரிகளில் "எங்கேயோ பார்த்த மயக்கம்". அநேகமாக, பாடல் வரிகள் எழுதி விட்டு பிறகு மெட்டு அமைத்திருப்பார்கள் என்று நம்புகிறேன். எனக்கு மிகவும் பிடித்த பல வரிகள் கொண்ட பாடல், குறிப்பாக, "இடி விழுந்த வீட்டில் இன்று பூச்செடிகள் பூக்கிறது" என்ற வரி. இந்தப் பாடலுக்கு என் வரிகளை, அதே காட்சிக்கு (Song Situation) பொருந்துமாறு, ஏதோ எனக்கு வந்த வரை எழுதி இருக்கிறேன். மெட்டோடு இயைந்து ஒலிக்கும் சொற்கள். கூடவே பாடிப் பாருங்கள்.
இந்தத் திரைப்படம் தெலுங்கில் செல்வராகவன் திரைக்கதை எழுதிய படத்தின் தமிழ் மொழிபெயர்ப்பு, திரு ரகுவரன் அவர்களின் இறுதிப் படமும் ஆகும்.
பாடல் குறித்து, ஏதேனும் கருத்து இருந்தால் பின்னூட்டத்தில் (Comments) தெரிவிக்கவும். ஏதாவது வரி புரியவில்லை என்றாலும் கேட்கவும். நன்றி.
பாடலின் சுட்டி:
இப்பாடல் மெட்டுக்கு என் வரிகள்:
உன்னோடு வாழ விருப்பம்! உன்நிழலில் கொண்டேன் கிறக்கம்! உன்னைப் பார்த்த நாளில் இருந்தே, நானும் கொண்டேன் காதல் மயக்கம்! கண்களை நீ இமைக்கும்போது, கூப்பிட்டாயென நம்பும் மனது.
என் தூக்கம் தூக்கிச் சென்ற பாவை, என் ஏக்கம் ஏற்றி வைத்த பூவை, இனி உனது நெருக்கம் எந்தன் தேவை, உனக்கு அளிப்பேன் எந்தன் வாழ்வை!
கால்கள் முளைத்த தாமரைநீயே! காற்றில் நகரும் ஓவியம்நீயே!
--- விழி கண்டேன் விழியே கண்டேன் வழியை மறந்து உன்னைக் கண்டேன் விழிகள் வழியே நீயும் நுழைய வலியைக் கொடுக்கும் காதல் கொண்டேன்
கொண்டேன் கொண்டேன் காதல் கொண்டேன் காற்றில் அலையும் காகிதம் போலே கவலை இன்றி திரிந்த நானும் கவிதைநூல் போல் காதல்கொண்டேன்
என்னோடு நீ, உன்னோடு நான் மெய்யோடு மெய் கலந்திட வேண்டும்
பாடி வந்த தேவதை நீதான் தேடி வந்த அடிமை நான்தான் கூடி நாமும் வாழ வேண்டும் ஓடிப் போவோம் உயிரே உடன்வா
-- (உன்னோடு வாழ விருப்பம்! ...)
இரவின் இருளைச் சிறைப்பிடித்து அதை விழியில் அடைத்து வைத் தாளோ நிலவின் குளுமையை எடுத்து தன் குரலில் இணைத்துக் கொண்ட தேன்மொழியோ
சிறகொடிந்த பறவை ஒன்று சிலிர்த்துக் கொண்டு எழுகிறது விரலிடுக்கில் உலகைத் தூக்கிப் பறந்து செல்ல விரைகிறது
பகலும் இரவும் உன்னை நினைத்து பசியும் ருசியும் மறந்து இளைத்து நினைவைப் பிழிந்து கவிதை வடித்து மனதை எடுத்து உனக்குக் கொடுத்து ...
... உன்னோடு வாழ விருப்பம்!
பிகு 1: ஏற்கனவே ஒரு முறை வேறொரு பாடலுக்கும் இப்படி ஒரு முயற்சி எடுத்திருக்கிறேன். பிகு 2: இந்த பாடல் வரிகளை நீங்கள் பாடுவதற்கோ, வேறு வியாபார நோக்கங்களுக்கோ வேண்டுமெனில் தாராளமாய் பயன்படுத்தவும். எனக்கு எந்த சன்மானமும் இதற்காக வேண்டாம் :) ஆனால் ஒரு அஞ்சல் அனுப்பி விட்டீர்கள் என்றால் மகிழ்வேன். இது CreativeCommons Zero License அடிப்படையில் உலகுக்கு அளிக்கப்படுகிறது.
The following screenshots don’t have the correct colours. Their colour channels got inverted because of this bug.
Brave testers of pre-release Fedora builds might have noticed the absence of updates to GNOME Terminal and VTE during the Fedora 28 development cycle. That’s no longer the case. Kalev submitted gnome-terminal-3.28.1 as part of the larger GNOME 3.28.1 mega-update, and it will make its way into the repositories in time for the Fedora 28 release early next month.
The recent lull in the default Fedora Workstation terminal was not due to the lack of development effort, though. The recent GNOME 3.28 release had a relatively large number of changes in both GNOME Terminal and VTE, and it took some time to update the Fedora-specificpatches to work with the new upstream version.
Here are some highlights from the past six months.
Unified preferences dialog
The global and profile preferences were merged into a single preferences dialog. I am very fond of this unified dialog because I have a hard time remembering whether a setting is global or not.
Text settings
The profile-specific settings UI has seen some changes. The bulk of these are in the “Text” tab, which used to be known as “General” in the past.
It’s now possible to adjust the vertical and horizontal spacing between the characters rendered by the terminal for the benefit of those with visual impairments. The blinking of the cursor can be more easily tweaked because the setting is now exposed in the UI. Some people are distracted by a prominently flashing cursor block in the terminal, but still want their thin cursors to flash elsewhere for the sake of discoverability. This should help with that.
Last but not the least, it’s nice to see the profile ID occupy a less prominent position in the UI.
Colours and bold text
There are somesubtleimprovements to the foreground colour selection for bold text. As a result, the “allow bold text” setting has been deprecated and replaced with “show bold text in bright colors” in the “Colors” tab. Various inconsistencies in the Tango palette were also resolved.
Port to GAction and GMenu
The most significant non-UI change was the port to GAction and GMenuModel. GNOME Terminal no longer uses the deprecated GtkAction and GtkUIManager classes.
If you don’t like it, then there’s a setting to turn it off.
Overline and undercurl
Similar to underline and strikethrough, VTE now supports overline and undercurl. These can be interesting for spell checkers and software development tools.
The reformed or simplified orthographic script style of Malayalam was introduced in 1971 by this government order. This is what is taught in schools. The text book content is also in reformed style. The prevailing academic situation does not facilitate the students to learn the exhaustive and rich orthographic set of Malayalam script. At the same time they observe a lot of wall writings, graffiti, bill-boards and handwriting sticking to the exhaustive orthographic set.
The sign marks for the vowels ഉ and ഊ (u and uː) have many diverse forms in the exhaustive orthographic set when joined with different consonants. But in the reformed style they are always detached from the base consonant with a unique form as ു and ൂ respectively for the vowel sounds u and uː. Everyone learns to read both of these orthographic variants either from the school or from everyday observations. But while writing the styles, they often gets mixed up as seen below.
u sign forms on wall writings
The green mark indicates the usage of reformed orthography to write പു (pu), blue indicates the usage of exhaustive set orthography to write ക്കു (kku). But the one in red is an unusual usage of exhaustive orthography to write ത്തു (ththu). Such usages are commonplace now, mainly due to the lack of academic training as I see it.
Redundant usage of vowel sign of u is indicated in circle
In this blog post I try to consolidate the vowel signs of u and uː referring to early script learning resources for Malayalam.
Vowel signs in Malayalam
There are 37 consonants and 15 vowels in Malayalam (additionally there are less popular consonant vowels like ൠ, ഌ and ൡ). Vowels have independent existence only at word beginnings. Otherwise they appear as consonant sound modifiers, in form of vowel signs. These signs often modify the glyph shape of consonants and this is a reason for the complex nature of Malayalam script. These marks can get distributed over the left and right of the base consonant. See the table below:
As seen in the table, the signs ു, ൂ, ൃ ([u] ,[uː], [rɨ] ) changes the shape of the base consonant grapheme. It was not until the 1971 orthographic reformation these signs got detached from the base grapheme. You can see the detached form as well in the rows 5,6 and 7 of the above table.
How does the vowel sign for ‘ു’ [u] and ‘ൂ’ [uː] affect the base consonant?
In the exhaustive script set of Malayalam there are in fact 8 ways in which ‘ു’ [u] and ‘ൂ’ [uː] sign marks change the shape of base consonant grapheme. These 8 forms (u- 4 forms and uː – 4 forms) are consolidated below.
‘ു’ [u] sign induces 4 types of shape variations to base consonant.
ക(ka) , ര(ra) gets modified by a shape we hereby call as hook. The same shape change applies to all conjuncts that ends with ക as in ങ്ക(n̄ka), ക്ക(kka), സ്ക(ska) and സ്ക്ക(skka). As the conjuncts that ends with ര(ra) assumes a special shape the hook shaped sign does not apply to them.
ഗ(ga), ഛ(ʧʰa), ജ(ʤa), ത(t̪a), ഭ(bʱa), ശ(ʃa), ഹ(ɦa) gets modified by a shape that resembles a tail that comes back to right after moving left. Those conjuncts which end with these consonants also assume the same tail shape when when ‘ു’ [u] vowel sign appear after them.
ണ(ɳa) and ന(na/n̪a) changes their shape with an inward closedloop. Those conjuncts which end with these consonants also assume the same loop shape when when ‘ു’ [u] vowel sign appear after them. For example ണ്ണ(ɳɳa), ന്ന(nna), ക്ന(kna) etc.
All other 24 consonants use the drop shape. As it is the most popular among all [u] signs, it is often mistakenly used instead of the other signs mentioned above. This case is indicated in the red circle in figure captioned u sign forms on wall writings.
‘ൂ’ [uː] sign induces 4 types of shape variations to base consonants.
ക(ka) , ര(ra), ഗ(ga), ഛ(ʧʰa), ജ(ʤa), ത(t̪a), ഭ(bʱa), ശ(ʃa), ഹ(ɦa) can have two alternate uː sign forms. First shape is hook and tailshape while the second one is hook and rounded tail.
Hook and rounded tail is more popular with the consonants ക(ka) , ര(ra) and ഭ(bʱa)
Hook and tail is more popular with the consonants ഗ(ga), ഛ(ʧʰa), ജ(ʤa), ത(t̪a), ശ(ʃa) and ഹ(ɦa)
The outward open loop shape is assumed by the ‘ൂ’ [uː] sign mark when associated with the consonants ണ(ɳa) and ന(na/n̪a)
All other 24 consonants use the double-drop shape. As it is the most popular among all [u] signs, it is often mistakenly used instead of the other signs mentioned above
Note: The sign shape names drop, double-drop, hook, hook and tail, hook and rounded tail, tail, closed loop and open loop are author’s own choice. Hence there is no citations to literature.
Early texts on Malayalam script and orthography
Modern textbooks do not detail the ‘ു’ [u] and ‘ൂ’ [uː] vowel sign forms. The earliest available reference to the script of Malayalam and its usage is the book from 1772, Alphabetum grandonico-malabaricum sive samscrudonicum.It was a text book meant to be used by western missionaries to Kerala to learn the Malayalam script and its language of description is Latin. Alphabetum describes various vowel sign forms but it does not give any indication on the hook and tail form. ക(ka) , ര(ra), ഗ(ga), ഛ(ʧʰa), ജ(ʤa), ത(t̪a), ഭ(bʱa), ശ(ʃa), ഹ(ɦa) etc. uses the hook and rounded tail form only. This being the first ever compilation of Malayalam script usage, that too by a non-native linguist, there are chances for unintended omissions about which I am not sure of.
The metal types used in this book were movable, and were the first of its kind to be used to print a Malayalam book. The same types were used to print the first ever complete book in Malayalam script – Samkshepavedartham.
Excerpt from Alphabetum grandonico-malabaricum sive samscrudonicum describing the usage of ‘ു’ [u] and ‘ൂ’ [uː] signsA still later work in this regard was done by Rev. George Mathan, almost a century later to Alphabetum. He introduces drop/double drop for ‘ു’ [u]/ ‘ൂ’ [uː] as the common sign form and all others shapes are indicated as exceptions. He clearly mentions about the two alternate forms of hook and tailas well as hook and rounded tail in his book on the Grammar of Malayalam.Grammar of Malayalam- George Mathan
Grammar of Malayalam- George Mathan
Contemporary usage of orthographic styles
The early attempts to describe the script of Malayalam with all its complexity is seen in these books in the initial days of printing era. Much later, in 1971 reformed script orthography was introduced to the language and culture aiming at overcoming the technological limitation of Malayalam typewriters. But the language users never abandoned the then existing style variants. Now we see around us a mix of all these styles.
Note: This is a translation of an earlier blog post written in Malayalam
આ છે, છેલ્લાં ૩ મહિનામાં જોયેલી ફિલમો. આ સિવાય પાસપોર્ટ ગુજરાતી ફિલમ બે દિવસ પહેલાં યુટ્યુબ પર મળી ગઇ, એકંદરે ઠીક કહેવાય. બ્લેડ રનર અને થ્રી બિલબોર્ડ્સ.. જોયા પછી જે ઝણઝણાટી થાય એવું બહુ ઓછી ફિલમોમાં થાય છે. જસ્ટિસ લીગ પણ ધાર્યા કરતા તો સરસ નીકળી છે. હવે કદાચ એવેન્જર્સ ૨૭ એપ્રિલે જોવા જઇશું એવો પ્લાન છે. રેવાનું ટ્રેલર જોયા પછી લાગે છે, એ ફિલમ સ્કિપ થશે. રતનપુર બાકી છે, અને ટ્રેલર પરથી સારી લાગી છે, એટલે જોવાનો ક્યાંકથી પ્રબંધ કરવો પડશે.
A branch of the Indian government, the Ministry of Information and
Broadcasting, is trying once again to censor Internet and Freedom of Speech.
This time, it ordered to form a
committee
of 10 members who will frame regulations for online media/ news portals and
online content.
This order includes these following Terms of Reference for the committee.
To delineate the sphere of online information dissemination which needs to be brought under regulation, on the lines applicable to print and electronic media.
To recommend appropriate policy formulation for online media / news portals and online content platforms including digital broadcasting which encompasses entertainment / infotainment and news/media aggregators keeping in mind the extant FDI norms, Programme & Advertising Code for TV Channels, norms circulated by PCI, code of ethics framed by NBA and norms prescribed by IBF; and
To analyze the international scenario on such existing regulatory mechanisms with a view to incorporate the best practices.
What are the immediate problems posed by this order?
If one reads carefully, one can see how vague are the terms, and specifically
how they added the term online content into it.
online content means everything we can see/read/listen do over cyberspace. In
the last few years, a number of new news organizations came up in India, whose
fearless reporting have caused a lot of problems for the government and their
friends. Even though they managed to censor publishing (sometimes self
censored) news in the mainstream Indian media, but all of these new online
media houses and individual bloggers and security researchers and activists
kept informing the mass about the wrongdoings of the people in power.
With this latest attempt to restrict free speech over the internet, the
government is trying to increase its reach even more. Broad terms like online
content platforms or online media or news/media aggregators will include
every person and websites under its watch. One of the impacts of mass
indiscriminate surveillance like this is that people are shamed into reading
and thinking only what is in line with the government, or popular thought .
How do you determine if some blog post or update in a social media platform is
news or not? For me, most of things I read on the internet are news to me. I
learn, I communicate my thoughts over these various platforms on cyberspace. To
all those computer people reading this blog post, think about the moment when
you will try to search about “how to do X in Y programming language?” on
Internet, but, you can not see the result because that is blocked by this
censorship.
India is also known for random
blockades of
different sites over the years. The Government also ordered to kill Internet
for entire states for many days. For the majority of internet blockages, we,
the citizens of India were neither informed the reasons nor given a chance to
question the legality of those bans. India has been marked as acountry under
surveillance by Reporters Without
Borders back in
2012.
Also remember that this is the same Government, which was trying to fight at
its best in the Supreme Court of India last year, to curb the privacy of every
Indian citizen. They said that Indian citizens do not have any right to
privacy. Thankfully the bench
declared
the following:
The right to privacy is protected as an intrinsic part of the right to life
and personal liberty under Article 21 and as a part of the freedoms guaranteed
by Part III of the Constitution.
Privacy is a fundamental right of every Indian citizen.
However, that fundamental right is still under attack in the name of another
draconian law The Aadhaar act. A case is currently going on in the Supreme
Court of India to determine the constitutional validity of Aadhaar. In the
recent past, when journalists reported how the Aadhaar data can be breached,
instead of fixing the problems, the government is criminally investigating the
journalists.
A Declaration of the Independence of Cyberspace
Different governments across the world kept trying (and they will keep trying
again and again) to curb free speech and press freedom. They are trying to draw
borders and boundaries inside of cyberspace, and restrict the true nature of
what is it referring to here?.
Governments of the Industrial World, you weary giants of flesh and steel, I
come from Cyberspace, the new home of Mind. On behalf of the future, I ask you
of the past to leave us alone. You are not welcome among us. You have no
sovereignty where we gather. -- John Perry Barlow
How can you help to fight back censorship?
Each and every one of us are affected by this, and we all can help to fight
back and resist censorship. The simplest thing you can do is start talking
about the problems. Discuss them with your neighbor, talk about it while
commuting to the office. Explain the problem to your children or to your
parents. Write about it, write blog posts, share across all the different
social media platforms. Many of your friends (from other fields than computer
technology) may be using Internet daily, but might not know about the
destruction these laws can cause and the censorship imposed on the citizens of
India.
Educate people, learn from others about the problems arising. If you are giving
a talk about a FOSS technology, also talk about how a free and open Internet is
helping all of us to stay connected. If that freedom goes away, we will lose
everything. At any programming workshop you attend, share these knowledge with
other participants.
In many cases, using tools to bypass censorship altogether is also very helpful
(avoiding any direct confrontation). The Tor
Project is a free software and open network which
helps to keep freedom and privacy of the users. By circumventing surveillance
and censorship, one can use it more for daily Internet browsing. The increase
in Tor traffic will help all of the Tor network users together. This makes any
attempt of tracking individuals even more expensive for any nation state
actors. So, download the Tor
Browser today and
start using it for everything.
In this era of Public private partnership from hell, Cory Doctorow
beautifully explained how internet is
the nervous system of 21st century, and how we all can join together to save
the freedom of internet. Listen to him, do your part.
dgplug summer training 2018 will start
at 13:30 UTC, 17th June. This will be the 11th edition. Like every year, we
have modified the training based on the feedback and, of course, there will be
more experiments to try and make it better.
What happened differently in 2017?
We did not manage to get all the guest sessions mentioned, but, we moved the
guest sessions at the later stage of the training. This ensured that only the
really interested people were attending, so there was a better chance of having
an actual conversation during the sessions. As we received mostly positive
feedback on that, we are going to do the same this year.
We had much more discussions among the participants in general than in previous
years. Anwesha and I wrote an
article
about the history of the Free Software and we had a lot of discussion about the
political motivation and freedom in general during the training.
We also had an amazing detailed session on Aadhaar and how it is affecting
(read destroying) India, by Kiran
Jonnalagadda.
Beside, we started writing a new book
to introduce the participants to Linux command line. We tried to cover the
basics of Linux command line and the tools we use on a day to day basis.
Shakthi Kannan started Operation Blue
Moon where he is helping
individuals to get things done by managing their own sprints. All information
on this project can be found in the aforementioned Github link.
What are the new plans in 2018?
We are living in an era of surveillance and the people in power are trying to
hide facts from the people who are being governed. There are a number of Free
Software projects which are helping the citizens of cyberspace to resist and
bypass the blockades. This year we will focus on these applications and how one
can start contributing to the same projects in upstream. A special focus will
be given to The Tor project, both from users’ and
developers’ point of views.
In 2017, a lot of people asked help to start learning Go. So, this year we will
do a basic introduction to Go in the training. Though, Python will remain the
primary choice for teaching.
How to join the training?
First, join our mailing list, and then join the IRC channel #dgplug on
Freenode.
In my previous blog post, I talked about how I improved the latency of GStreamer's default audio capture and render elements on Windows.
An important part of any such work is a way to accurately measure the latencies in your audio path.
Ideally, one would use a mechanism that can track your buffers and give you a detailed breakdown of how much latency each component of your system adds. For instance, with an audio pipeline like this:
If you use GStreamer, you can use the latency tracer to measure how much latency filter1 adds, filter2 adds, and so on.
However, sometimes you need to measure latencies added by components outside of your control, for instance the audio APIs provided by the operating system, the audio drivers, or even the hardware itself. In that case it's really difficult, bordering on impossible, to do an automated breakdown.
But we do need some way of measuring those latencies, and I needed that for the aforementioned work. Maybe we can get an aggregated (total) number?
There's a simple way to do that if we can create a loopback connection in the audio setup. What's a loopback you ask?
Essentially, if we can redirect the audio output back to the audio input, that's called a loopback. The simplest way to do this is to connect the speaker-out/line-out to the microphone-in/line-in with a two-sided 3.5mm jack.
Now, when we send an audio wave down to the audio output, it'll show up on the audio input.
Hmm, what if we store the current time when we send the wave out, and compare it with the current time when we get it back? Well, that's the total end-to-end latency!
If we send out a wave periodically, we can measure the latency continuously, even as things are switched around or the pipeline is dynamically reconfigured.
Some of you may notice that this is somewhat similar to how the `ping` command measures latencies across the Internet.
Just like a network connection, the loopback connection can be lossy or noisy, f.ex. if you use loudspeakers and a microphone instead of a wire, or if you have (ugh) noise in your line. But unlike network packets, we lose all context once the waves leave our pipeline and we have no way of uniquely identifying each wave.
So the simplest reliable implementation is to have only one wave traveling down the pipeline at a time. If we send a wave out, say, once a second, we can wait about one second for it to show up, and otherwise presume that it was lost.
The first measurement will always be wrong because of various implementation details in the audio stack, but the next measurements should all be correct.
This mechanism does place an upper bound on the latency that we can measure, and on how often we can measure it, but it should be possible to take more frequent measurements by sending a new wave as soon as the previous one was received (with a 1 second timeout). So this is an enhancement that can be done if people need this feature.
I dream of a day, and it is not a crazy dream, when everybody on this planet
who wants to know all about that is presently known about something, will be
able to do so regardless of where he or she is. And and I dream of a day where
the right to know is understood as a natural human right, that extends to every
being on the planet who is governed by anything. The right to know what it’s
government is doing and how and why. -- John Perry Barlow
I met John Perry Barlow only
once in my life, during his PyCon US 2014 keynote. I remember trying my best
to stay calm as I walked towards him to start a conversation. After some time,
he went up on the stage and started speaking. Even though I spoke with him
very briefly, I still felt like I knew him for a long time.
The event started around 2:30AM IST, and Anwesha and /me woke up at right time
to attend the whole event. Farhaan and Saptak also took part in watching the
event live.
Cory Doctorow was set to open the event but was late due to closing down of SFO
runways (he later mentioned that he was stuck for more than 5 hours). In his
stead, Cindy Cohn, Executive Director of the Electronic Frontier Foundation,
started the event. There were two main panel sessions, with 4 speakers in each,
and everyone spoke about how Barlow inspired them, or about Internet freedom,
and took questions after. But, before those sessions began, Ana Barlow spoke
about her dad, and about how many people from different geographies were
connected to JPB, and how he touched so many people’s lives.
The first panel had Mitch Kapor, Pam Samuelson, Trevor Timm on the stage. Mitch
started talking with JPB’s writing from 1990s and how he saw the future of
Internet. He also reminded us that most of the stories JPB told us, were
literally true :D. He reminded us even though EFF started as a civil liberties
organization, but how Wall Street Journal characterized EFF as a hacker
defense fund. Pam Samuelson spoke next starting with a quote from JPB. Pam
mentioned The Economy of Ideas
published in 1994 in the Wired magazine as the Barlow’s best contribution to
copyrights.
Cory Doctorow came up on stage to introduce the next speaker, Trevor Timm, the
executive director of Freedom of the Press Foundation (FPF). He particularly
mentioned SecureDrop project and the importance of
it. I want to emphasize one quote from him.
It’s been observed that many people around the world, billions of people
struggle under bad code written by callow silicon valley dude bros, those who
hack up a few lines of code and then subject billions of people to it’s
outcomes without any consideration of ethics.
Trevor talked about the initial days of Freedom of the Press Foundation, and
how JPB was the organizational powerhouse behind the organization. On the day
FPF was launched, JPB and Daniel Ellsberg wrote an
article
for Huffingtonpost, named Crowd Funding the Right to Know.
When a government becomes invisible, it becomes unaccountable. To expose its
lies, errors, and illegal acts is not treason, it is a moral responsibility.
Leaks become the lifeblood of the Republic.
After few months of publishing the above mentioned article, one government
employee was moved by the words, and contacted FPF board members (through
Micah Lee). Later when his name become public,
Barlow posted the following tweet.
Next, Edward Snowden himself came in as the 4th speaker in the panel. He told a
story which is not publicized much. He went back to his days in NSA where even
though he was high school drop out, he had a high salary and very comfortable
life. As he gained access to highly classified information, he realized that
something was not right.
I realized what was legal, was not necessarily what was moral. I realized
what is being made public, was not the same of what was true. -- Edward
Snowden.
He talked about how EFF and JPB’s work gave direction of many decisions of his
life. Snowden read Barlow’s A Declaration of the Independence of
Cyberspace and perhaps that was
the first seed of radicalization in his life. How Barlow choose people over
living a very happy and easy life, shows his alliance with us, the common
people of the world.
After the first panel of speakers, Cory again took the stage to talk about
privacy and Internet. He spoke about why building technology which are safe for
world is important in this time of the history.
After a break of few minutes, the next panel of speakers came up on the stage,
the panel had Shari Steele, John Gilmore, Steven Levy, Joi Ito.
Shari was the first speaker in this group. While started talking about the
initial days of joining EFF, she mentioned how even without knowing about JPB
before, only one meeting converted Shari into a groupie. Describing the first
big legal fight of EFF, and how JPB wrote A Declaration of the Independence of
Cyberspace during that time. She chose a quote from the same:
We are creating a world where anyone, anywhere may express his or her beliefs,
no matter how singular, without fear of being coerced into silence or
conformity.
Later, John Gilmore pointed out a few quotes from JPB on LSD and how the
American society tries to control everything. John explained why he thinks
Barlow’s ideas were correct when it comes to psychedelic drugs and the effects
on human brains. He mentioned how JPB cautioned us about distinguishing the
data, information and the experience, in ways that are often forgotten today.
Next, Steven Levy kept skipping many different stories, choosing to focus on
how amazingly Barlow decided to express his ideas. The many articles JPB wrote,
helped to transform the view of web in our minds. Steven chose a quote from
JPB’s biography (which will be published in June) to share with us:
If people code out for eight minutes like I did and then come back, they
usually do so as a different person than the one who left. But I guess my brain
doesn’t use all that much oxygen because I appeared to be the same guy, at
least from the inside. For eight minutes, however, I had not just been
gratefully dead, I had been plain, flat out, ordinary dead. It was then I
decided the time had finally come for me to begin working on my book. Looking
for a ghost writer was not really the issue. At the time, my main concern was
to not be a ghost before the book itself was done.
I think Steven Levy chose the right words to describe Barlow in the last
sentence of his talk:
Reading that book, makes me think that how much we are going to miss Barlow’s
voice in this scary time for tech when our consensual hallucination is looking
more and more like a bad trip.
When you talk to Dalai Lama, just like when you talk to John Perry Barlow,
there is a deep sense of humor that comes from knowing how f***** up the world
is, how unjust the world is, how terrible it is, but still being so connected
to true nature, that it is so funny. -- Joi Ito
Joi mentioned that Barlow not only gave a direction to us by writing the
declaration of the independence of cyberspace, but, he also created different
organizations to make sure that we start moving that direction.
Amelia Barlow was the last speaker of the day. She went through the 25
Principles of Adult Behavior.
The day ended with a marching order from Cory Doctorow. He asked everyone to
talk more about the Internet and technologies and how they are affecting our
lives. If we think that everyone can understand the problems, that will be a
very false hope. Most people still don’t think much about freedom and how the
people in power control our lives using the same technologies we think are
amazing. Talking to more people and helping them to understand the problem is a
good start to the path of having a better future. And John Perry Barlow showed
us how to walk on that path with his extraordinary life and willfulness of
creating special bonds with everyone around him.
I want to specially thank the Internet Archive for
hosting the event and allowing the people like uswe who are in the cyberspace to
actually get the feeling of being in the room with everyone else.
Compared to analog audio, digital audio processing is extremely versatile, is much easier to design and implement than analog processing, and also adds effectively zero noise along the way. With rising computing power and dropping costs, every operating system has had drivers, engines, and libraries to record, process, playback, transmit, and store audio for over 20 years.
Today we'll talk about the some of the differences between analog and digital audio, and how the widespread use of digital audio adds a new challenge: latency.
Analog vs Digital
Analog data flows like water through an empty pipe. You open the tap, and the time it takes for the first drop of water to reach you is the latency. When analog audio is transmitted through, say, an RCA cable, the transmission happens at the speed of electricity and your latency is:
This number is ridiculously small—especially when compared to the speed of sound. An electrical signal takes 0.001 milliseconds to travel 300 metres (984 feet). Sound takes 874 milliseconds (almost a second).
All analog effects and filters obey similar equations. If you're using, say, an analog pedal with an electric guitar, the signal is transformed continuously by an electrical circuit, so the latency is a function of the wire length (plus capacitors/transistors/etc), and is almost always negligible.
Digital audio is transmitted in "packets" (buffers) of a particular size, like a bucket brigade, but at the speed of electricity. Since the real world is analog, this means to record audio, you must use an Analog-Digital Converter. The ADC quantizesthe signal into digital measurements (samples), packs multiple samples into a buffer, and sends it forward. This means your latency is now:
We saw above that the first part is insignificant, what about the second part?
Latency is measured in time, but buffer size is measured in bytes. For 16-bit integer audio, each measurement (sample) is stored as a 16-bit integer, which is 2 bytes. That's the theoretical lower limit on the buffer size. The sample rate defines how often measurements are made, and these days, is usually 48KHz. This means each sample contains ~0.021ms of audio. To go lower, we need to increase the sample rate to 96KHz or 192KHz.
However, when general-purpose computers are involved, the buffer size is almost never lower than 32 bytes, and is usually 128 bytes or larger. For single-channel 16-bit integer audio at 48KHz, a 32 byte buffer is 0.33ms, and a 128 byte buffer is 1.33ms. This is our buffer size and hence the base latency while recording (or playing) digital audio.
Digital effects operate on individual buffers, and will add an additional amount of latency depending on the delay added by the CPU processing required by the effect. Such effects may also add latency if the algorithm used requires that, but that's the same with analog effects.
The Digital Age
So everyone's using digital. But isn't 1.33ms a lot of additional latency?
It might seem that way till you think about it in real-world terms. Sound travels less than half a meter (1½ feet) in that time, and that sort of delay is completely unnoticeable by humans—otherwise we'd notice people's lips moving before we heard their words.
In fact, 1.33ms is too small for the majority of audio applications!
To process such small buffer sizes, you'd have to wake the CPU up 750 times a second, just for audio. This is highly inefficient, and wastes a lot of power. You really don't want that on your phone or your laptop, and is completely unnecessary in most cases anyway.
For instance, your music player will usually use a buffer size of ~200ms, which is just 5 CPU wakeups per second. Note that this doesn't mean that you will hear sound 200ms after hitting "play". The audio player will just send 200ms of audio to the sound card at once, and playback will begin immediately.
Of course, you can't do that with live playback such as video calls—you can't "read-ahead" data you don't have. You'd have to invent a time machine first. As a result, apps that use real-time communication have to use smaller buffer sizes because that directly affects the latency of live playback.
That brings us back to efficiency. These apps also need to conserve power, and 1.33ms buffers are really wasteful. Most consumer apps that require low latency use 10-15ms buffers, and that's good enough for things like voice/video calling, video games, notification sounds, and so on.
Ultra Low Latency
There's one category left: musicians, sound engineers, and other folk that work in the pro-audio business. For them, 10ms of latency is much too high!
You usually can't notice a 10ms delay between an event and the sound for it, but when making music, you can hear it when two instruments are out-of-sync by 10ms or if the sound for an instrument you're playing is delayed. Instruments such as drum snare are more susceptible to this problem than others, which is why the stage monitors used in live concerts must not add any latency.
The standard in the music business is to use buffers that are 5ms or lower, down to the 0.33ms number that we talked about above.
Power consumption is absolutely no concern, and the real problems are the accumulation of small amounts of latencies everywhere in your stack, and ensuring that you're able to read buffers from the hardware or write buffers to the hardware fast enough.
Let's say you're using an app on your computer to apply digital effects to a guitar that you're playing. This involves capturing audio from the line-in port, sending it to the application for processing, and playing it from the sound card to your amp.
The latency while capturing and outputting audio are both multiples of the buffer size, so it adds up very quickly. The effects app itself will also add a variable amount of latency, and at 1.33ms buffer sizes you will find yourself quickly approaching a 10ms latency from line-in to amp-out. The only way to lower this is to use a smaller buffer size, which is precisely what pro-audio hardware and software enables.
The second problem is that of CPU scheduling. You need to ensure that the threads that are fetching/sending audio data to the hardware and processing the audio have the highest priority, so that nothing else will steal CPU-time away from them and cause glitching due to buffers arriving late.
This gets harder as you lower the buffer size because the audio stack has to do more work for each bit of audio. The fact that we're doing this on a general-purpose operating system makes it even harder, and requires implementing real-time scheduling features across several layers. But that's a story for another time!
I hope you found this dive into digital audio interesting! My next post will be is about my journey in implementing ultra low latency capture and render on Windows in the WASAPI plugin for GStreamer. This was already possible on Linux with the JACK GStreamer plugin and on macOS with the CoreAudio GStreamer plugin, so it will be interesting to see how the same problems are solved on Windows. Tune in!
સ્ટ્રાવા એપ સાથે સૌથી મોટી તકલીફ ઘણી વખત જીપીએસના લોચા છે. આ એપ ફોનના જીપીએસ પર આધારિત છે અને ફોનનું જીપીએસ તેમાં રહેેલી ચીપ પર. તેમાં આવતી ચીપ કઇ કંપનીની છે, તે આધારિત છે ફોનની કિંમત પર. એટલે સસ્તો ફોન, સસ્તું પરિણામ. જોકે એનો અર્થ એ નહી કે સ્ટ્રાવામાં મુશ્કેલી આવે જ. છતાં પણ આવે તો,
૧. મોબાઇલમાં બેટ્રી ઓપ્ટિમાઇઝર સ્ટ્રાવા એપ માટે બંધ કરી દેવું.
૨. શક્ય હોય તો મોબાઇલ નેટવર્ક સ્ટ્રાવા શરૂ કર્યા પછી બંધ કરી દેવું. જેથી વધુ બેટ્રી ન વપરાય અને જીપીએસ મોબાઇલ ટાવરને પકડે નહી.
૩. સ્ટ્રાવા ડેસ્કટોપ પર અંતર અને ઉંચાઇ ખોટી આવે તો સુધારી શકાય છે. વધુમાં, રાઇડ-રનને કટ-ક્રોપ પણ કરી શકાય છે.
૪. ગારમિન કે જીપીએસ ઘડિયાળ વાપરવી
The Tor network provides a safer way to access
the Internet, without local ISP and government recording your every step on the
Internet. We can use the same network to chat over IRC. For many FOSS
contributors and activists across the world, IRC is a very common medium for a
chat. In this blog post, we will learn about how to use ZNC with Tor for IRC.
Introducing ZNC
ZNC is an IRC bouncer program, which will allow your
IRC client to stay detached from the server, but still receive and log the
messages, so that when you connect a client later on, you will receive all the
messages.
In this tutorial, we will use znc-1.6.6 (packaged in Fedora and EPEL). I am
also going to guess that you already figured out the basic
usage of ZNC.
Installing the required tools
$ sudo dnf install znc tor torsocks
Tor provides a SOCKS proxy at port 9050 (default value), but, ZNC cannot use
a SOCKS proxy easily. We will use torify command from torsocks package to use
the SOCKS proxy.
ZNC service over Tor network
As a first step, we will make sure that we have the listener at the ZNC service
listening as an Onion service. First, we will edit our /etc/tor/torrc file
and add the following.
After this, when we start the tor service, we will be able to find the
.onion address and the HidServAuth value from the
/var/lib/tor/hidden_service/hostname file.
Here, I am making sure that the listener only listens to the localhost. We
already mapped the port 8001 of localhost to our Onion service. This way the
web frontend of ZNC is only available over Tor.
Now you can start service, I will keep it running in the foreground along with
debugging messages to make sure that things are working.
$ torify znc --debug
Connecting from web client
I am using xchat as the IRC client. I also have Tor installed on my local
computer and added the following line the /etc/tor/torrc file so that my
system can find and connect to the Onion service.
If you just want to connect to the ZNC web frontend using the Tor Browser, then
you will have to add the same line the Browser/TorBrowser/Data/Tor/torrc
inside of the Tor Browser.
Connecting to OFTC network
Now we will connect to the OFTC IRC network. The Tor
Project itself has all the IRC channels on this
network. Make sure that you have a registered IRC nickname on this network.
Add the following configuration in the ZNC configuration file.
Now let us start xchat with torify so that it can find our onion service.
$ torify xchat
Next, we will add our new ZNC service address as a new server, remember to have
the password as zncusername/networkname:password. In the above case, the
network name is oftc.
After adding the new server as mentioned above, you should be able to connect
to it using xchat.
Connecting to Freenode network
Freenode provides an Onion service to
it’s IRC network. This means your connection from the client (ZNC in this case)
to the server is end-to-end encrypted and staying inside of the Onion network
itself. But, using this will require some extra work.
Creating SSL certificate for Freenode
On the server, we will have to create an SSL certificate.
The Jump command will try to reconnect to the Freenode IRC server. You should
be able to see the debug output in the server for any error.
The story of the server fingerprint for Freenode
Because Freenode’s SSL certificate is not an EV certificate for the .onion
address, ZNC will fail to connect normally. We will have to add the server
fingerprint to the configuration so that we can connect. But, this step was
failing for a long time, and the excellent folks in #znc helped me to debug the
issue step by step. It seems the fingerprint given on the Freenode
site is an old one, and we need the
current fingerprint. We also have an
issue filed on a related note.
Finally, you may want to run the ZNC as a background process on the server.
$ torify znc
Tools versions
ZNC 1.6.6
tor 0.3.2.10
torsocks 2.2.0
If you have queries, feel free to join #znc on Freenode and #tor on OFTC
network and ask for help.
Updated post
I have updated the post to use torify command. This will make running znc much
simpler than the tool mentined previously.
I recently read Jérôme Petazzoni’s blog post about a tool called AppSwitch which made some Twitter waves on the busy interwebz. I was intrigued. It turns out that it was something that I was familiar with. When I met Dinesh back in 2015 at Linux Plumbers in Seattle, he had presented me with a grand vision of how applications needs to be free of any networking constraints and configurations and a uniform mechanism should evolve that make such configurations transparent (I’d rather say opaque now). There are layers over layers of network related abstractions. Consider a simple network call made by a java application. It goes through multiple layers in userspace (though the various libs, all the way to native calls from JVM and eventually syscalls) and then multiple layers in kernel-space (syscall handlers to network subsytems and then to driver layers and over to the hardware). Virtualization adds 4x more layers. Each point in this chain does have a justifiable unique configuration point. Fair point. But from an application’s perspective, it feels like fiddling with the knobs all the time :
For example, we have of course grown around iptables and custom in-kernel and out of kernel load balancers and even enhanced some of them to exceptional performance (such as XDP based load balancing). But when it comes to data path processing, doing nothing at all is much better than doing something very efficiently. Apps don’t really have to care about all these myriad layers anyway. So why not add another dimension to this and let this configuration be done at the app level itself? Interesting..
I casually asked Dinesh to see how far the idea had progressed and he ended up giving me a single binary and told me that’s it! It seems AppSwitch had been finally baked in the oven.
First Impressions
So there is a single static binary named ax which runs as an executable as well as in a daemon mode. It seems AppSwitch is distributed as a docker image as well though. I don’t see any kernel module (unlike what Jerome tested). This is definitely the userspace version of the same tech.
I used the ax docker image. ax was both installed and running with one docker-run command.
Based on the documentation, this little binary seems to do a lot — service discovery, load balancing, network segmentation etc. But I just tried the basic features in a single-node configuration.
# ax run --ip 1.2.3.4 -- java -jar SimpleWebServer.jar
This starts the webserver and assigns the ip 1.2.3.4 to it. Its like overlaying the server’s own IP configurations through ax such that all request are then redirected through 1.2.3.4. While idling, I didn’t see any resource consumption in the ax daemon. If it was monitoring system calls with auditd or something, I’d have noticed some CPU activity. Well, the server didn’t break, and when accessed via a client run through ax, it starts serving just fine.
# ax run --ip 5.6.7.8 -- curl -I 1.2.3.4
HTTP/1.0 500 OK
Date: Wed Mar 28 00:19:25 PDT 2018
Server: JibbleWebServer/1.0
Content-Type: text/html
Expires: Thu, 01 Dec 1994 16:00:00 GMT
Content-Length: 58Last-modified: Wed Mar 28 00:19:25 PDT 2018
Naaaice! Why not try connecting with Firefox. Ok, wow, this works too!
I tried this with a Golang http server (Caddy) that is statically linked. If ax was doing something like LD_PRELOAD, that would trip it up. This time I tried passing a name rather than the IP and ran it as regular user with a built-in --useroption
# ax run --myserver --user suchakra -- caddy -port 80
# ax run --user suchakra -- curl -I myserver
HTTP/1.1 200 OK
Accept-Ranges: bytes
Content-Length: 0
Content-Type: text/html; charset=utf-8
Etag: "p6f4lv0"
Last-Modified: Fri, 30 Mar 2018 19:25:07 GMT
Server: Caddy
Date: Sat, 31 Mar 2018 01:52:28 GMT
So no kernel module tricks, it seems. I guess this explains why Jerome called it “Network Stack from the future”. The future part here is applications and with predominant containerized deployments, the problems of microservices networking have really shifted near to the apps.
We need to get rid of the overhead caused by networking layers and frequent context switches happening as a single containerized app communicates with another one. AppSwitch could potentially just eliminate this all together and the communication would actually resemble traditional socket based IPC mechanisms with an advantage of a zero overhead read/write cost once the connection is established. I think I would want to test this out thoroughly sometime in the future if i get some time off from my bike trips
How does it work?
Frankly I don’t know in-depth, but I can guess. All applications, containerized or not, are just a bunch of executables linked to libs (or built statically) running over the OS. When they need OS’s help, they ask. To understand an application’s behavior or to morph it, OS can help us understand what is going on and provide interfaces to modify its behavior. Auditd for example, when configured, can allow us to monitor every syscall from a given process. Programmable LSMs can be used to set per-resource policies through kernel’s help. For performance observability, tracing tools have traditionally allowed an insight into what goes on underneath. In the world of networking, we again take the OS’s help – routing and filtering strategies are still defined through iptables with some advances happening in BPF-XDP. However, in the case of networking, calls such as connect(), accept() could be intercepted purely in userspace as well. But doing so robustly and efficiently without application or kernel changes with reasonable performance has been a hard academic problem for decades [1][2]. There must be some other smart things at work underneath in ax to keep this robust enough for all kinds of apps. With interception problem solved, this would allow ax to create a map and actually perform the ‘switching’ part (which I suppose justifies the AppSwitch name). I have tested it presently on a Java, Go and a Python server. With network syscall interception seemingly working fine, the data then flows like hot knife on butter. There may be some more features and techniques that I may have missed though. Going through ax --help it seems there are some options for egress, WAN etc, but I haven’t played it with that much.
Few months ago, I was talking to Siva. He is part of Tamil Heritage Activities. They take people to Mahabalipuram often and explain all its great history.
They are looking for a mobile app to auto explain about the nearby place, by getting the geolocation of the person.
if you goto near to tiger cave of mahabalipuram, the app should explain all about tiger cave. The data can be provided from a wikipedia page or some custom webservice.
We can extend the same to any place. Like, extending the same for all the temples in kanchipuram or even all over world.
Wikipedia and wikidata can be great starting points for providing required information.
Now, we are looking for android/ios developers to develop this as an open source mobile application.
If you are interested in this, mail me on tshrinivasan@gmail.com or reply here.
Hidden away in the farthest corner of the planet, its slopes covered in mist and darkness and its peaks lost in the clouds, stands the formidable Mount GNOME. Perched atop the mountain is a castle as menacing as the mountain itself – its towering walls made of stones as cold as death, and the wind howling through the courtyard like a dozen witches screaming for blood.
Living inside the imposing blackness are a group of feral savages, of whom very little is known to the world outside. The deathly walls of the castle bear testimony to their skull-crushing barbarism, and their vile customs have laid waste to the surrounding slopes and valleys. Mortally fearful of invoking their mad wrath, no human traveller has dared to come near the vicinity of their territory. Shrouded in anonymity, they draw their name from the impregnable mountain that they inhabit – they are the GNOME people.
Legend has it that they are unlike any human settlement known to history. Some say that they are barely human. They are like a foul amorphous mass that glides around Mount GNOME, filling the air with their fiendish thoughts, and burning every leaf and blade of grass with their fierce hatred. Living in an inferno of collectivism, the slightest notion of individuality is met with the harshest of punishments. GNOMEies are cursed with eternal bondage to the evil spirits of the dark mountain.
We just released 1.9.11 and 1.10.3 versions of Ant today. The downloads are available on the Ant project's download page. Both these releases are mainly bug fix releases, especially the 1.9.11 version. The 1.10.3 release is an important one for a couple of reasons. The previous 1.10.2 release, unintentionally introduced a bunch of changes which caused regressions in various places in Ant tasks. These have now been reverted or fixed in this new 1.10.3 version.
In addition to these fixes, this 1.10.3 version of Ant introduces a new junitlauncher task. A while back, the JUnit team has released JUnit 5.x version. This version is a major change from previous JUnit 3.x & 4.x versions, both in terms of how tests are written and how they are executed. JUnit 5 introduces a separation between test launching and test identification and execution. What that means is, for build tools like Ant, there's now a clear API exposed by JUnit 5 which is solely meant to deal with how tests are launched. Imagine something along the lines of "launch test execution for classes within this directory". Although Ant's junit task already supported such construct, the way we used to launch those tests was very specific to Ant's own implementation and was getting more and more complex. With the introduction of this new API within the JUnit 5 library, it's much more easier and consistent now to launch these tests.
JUnit 5, further introduces the concept of test engines. Test engines are responsible for "identifying" which classes are actually tests and what semantics to apply to those tests. JUnit 5 by default comes with a "vintage" engine which identifies and runs JUnit 4.x style tests and a "jupiter" engine which identifies and runs JUnit 5.x API based tests.
The "junitlauncher" task in Ant introduces a way to let the build specify which classes to choose for test launching. The goal of this task is to just launch the test execution and let the JUnit 5 framework identify and run the tests. The current implementation shipped in Ant 1.10.3, is the basic minimal for this task. We plan to add more features as we go along and as we get feedback on it. Especially, this new task doesn't currently support executing these tasks in a separate forked JVM, but we do plan to add that in a subsequent release.
The junit task which has been shipped in Ant since long time back, will continue to exist and can be used for executing JUnit 3.x or JUnit 4.x tests. However, for JUnit 5 support, the junitlauncher task is what will be supported in Ant.
આ શ્રેણીમાં ચોથી પોસ્ટ. ગઇકાલે ત્રીજી પોસ્ટ કરી ત્યારે નિઝિલે કહ્યું કે સ્ટ્રાવા ઓપનસ્ટ્રીટમેપનો નકશો વાપરે છે તે સારું કહેવાય. હા. સ્ટ્રાવાનો નકશો અધૂરો જોઇને જ મારું ઓપનસ્ટ્રીટમેપનું યોગદાન શરૂ થયેલું. આપણી ફેવરિટ જગ્યાઓ જેવી કે માસ્ટરમાઇન્ડ, સિક્રેટ સ્પાઇસ (બી.આર.એમ.ની જગ્યા), વિવિધ ચા વાળાઓ, આજુ-બાજુના બિલ્ડિંગો, અગત્યના પોઇન્ટ્સ વગેરે સ્ટ્રાવાને કારણે જ ઉમેરવામાં આવ્યા છે. સ્ટ્રાવા મોબાઇલ એપ્સમાં ગુગલ મેપ્સ વાપરે છે, જે ખટકે છે, પણ ઠીક છે. સ્ટ્રાવના જીપીએસ તમે ઓપનસ્ટ્રીટમેપમાં અપલોડ કરી શકો છો. જોકે હું ઓફરોડિંગ કરતો નથી એટલે આ તક હજુ મળી નથી. હાઇકિંગ અને ટ્રેકિંગ કરતા લોકોએ અહીં યોગદાન આપવા જેવું છે.
૧૨ વર્ષ પહેલાં આ બ્લોગ શરૂ થયેલો આ બ્લોગ હજુ ટીનએજર્સ બન્યો નથી. હજુ સુધી તો બ્લોગ-બ્લોગિંગમાં મઝા આવે છે. જોઇએ હવે ક્યારે આ મઝા પૂરી થાય છે. બ્લોગ-રનિંગ-સાયકલિંગ-જીવન. કોને અગ્રતા આપવી એ હજુ નક્કી નથી, પણ અત્યારે આ ચાર વસ્તુઓ લગભગ સમાંતર ચાલે છે. કોઇક વખત એમાંથી કોઇ આગળ નીકળે છે અને કોઇ પાછળ રહી જાય છે. પણ, એકંદરે ચારેયમાંથી કોઇ હાંફ્યું નથી.
એક સંબંધિત અને સરસ સમાચાર: ચંદ્રકાંત બક્ષી અને અન્ય કેટલાય લેખકોના મસ્ત ફોટાઓ સંજયભાઇએ વિકિપીડિયામાં અપલોડ કર્યા છે. કેટલાય વર્ષોની ઇચ્છા ફળી છે. સંજયભાઇ અને અનંતનો આભાર અને તેમના પરથી કેટલાય લોકો પ્રેરણા લે તેવી ઇચ્છા!
આ પોસ્ટ સ્ટ્રાવા શ્રેણીમાં ત્રીજી પોસ્ટ છે. આ વાત છે એક સાથે બે-ત્રણ ડિવાઇસ-મોબાઇલ-ગારમિન કે પછી ઘડિયાળોમાં સ્ટ્રાવાની એક્ટિવિટી રેકોર્ડ કરીને અપલોડ કરતા લોકો માટે. અમુક લોકોને પોતાની એક્ટિવિટી એટલી હદે ગમે કે ગમે તે થાય તેને રેકોર્ડ કરીને અપલોડ કરવી જ. ઘણી વખત એવું થાય કે ફોન કે પછી ગારમિન છેલ્લી ઘડીએ દગો દે અને રાઇડ કે રન રેકોર્ડ જ ન થાય (મારી સાથે એવું એક-બે વખત બન્યું છે, એમાં પણ એક વખત તો રેસમાં). આવું ટાળવા માટે લોકો બે ડિવાઇસ (દા.ત. ગારમિન અને ફોન બંનેમાં) રેકોર્ડ કરે. રેકોર્ડ કરે તો વાંધો નહી પણ સ્ટ્રાવા પર પણ અપલોડ કરે. એટલે એવું આવે, “કાર્તિક મિસ્ત્રી ગ્રુપ રાઇડ વિથ કાર્તિક મિસ્ત્રી”. એટલે કે હું સાઇકલ ચલાવું છું, મારી સાથે! હા, આવી રાઇડ અપલોડ થાય તો પણ વાંધો નહી પણ બંને રાઇડમાંથી એક રાઇડ તો દૂર કરો! પણ લોકો સમજતા જ નથી
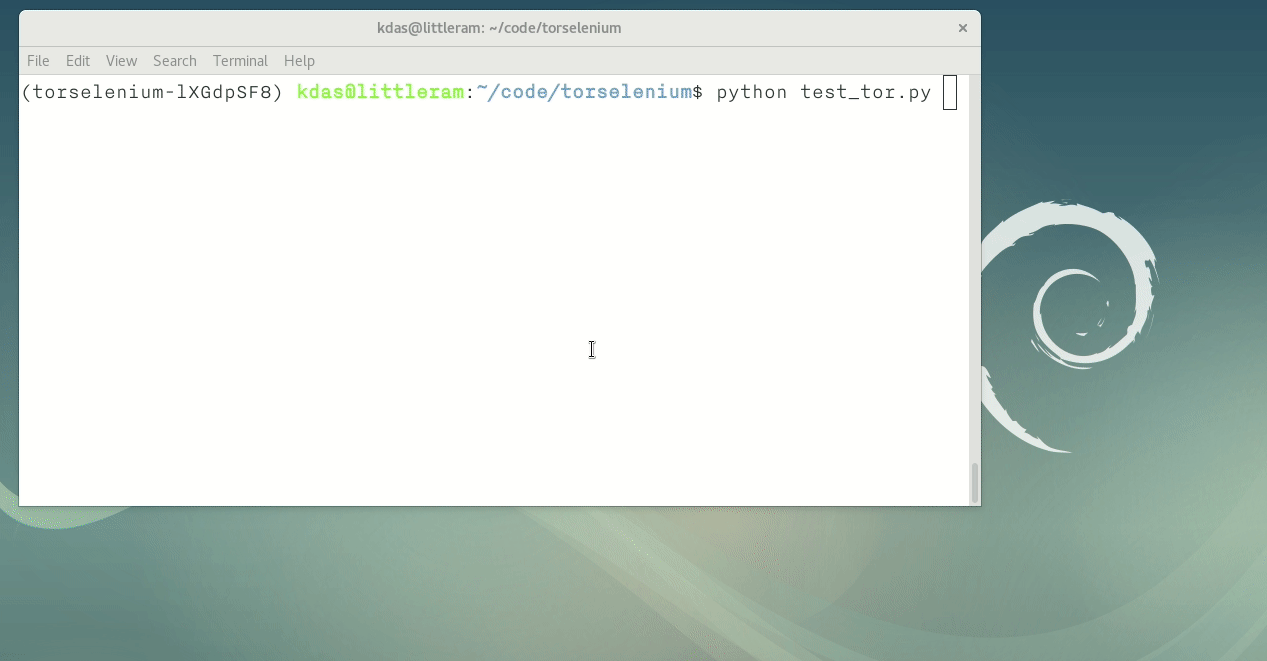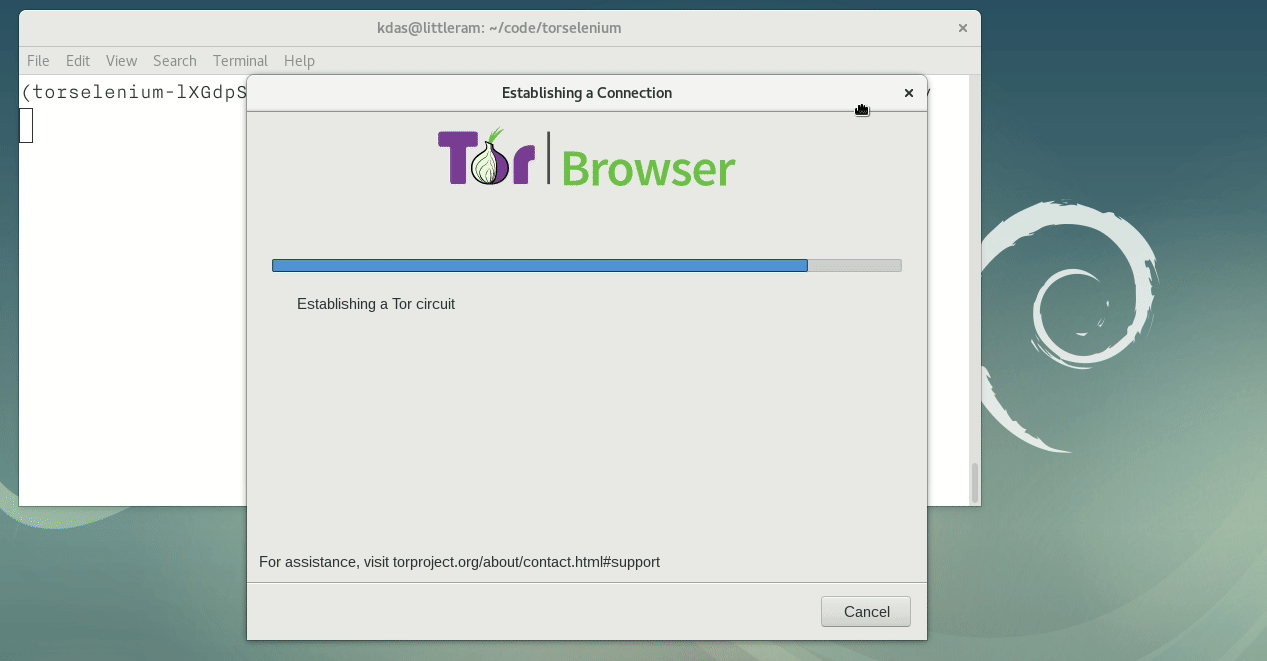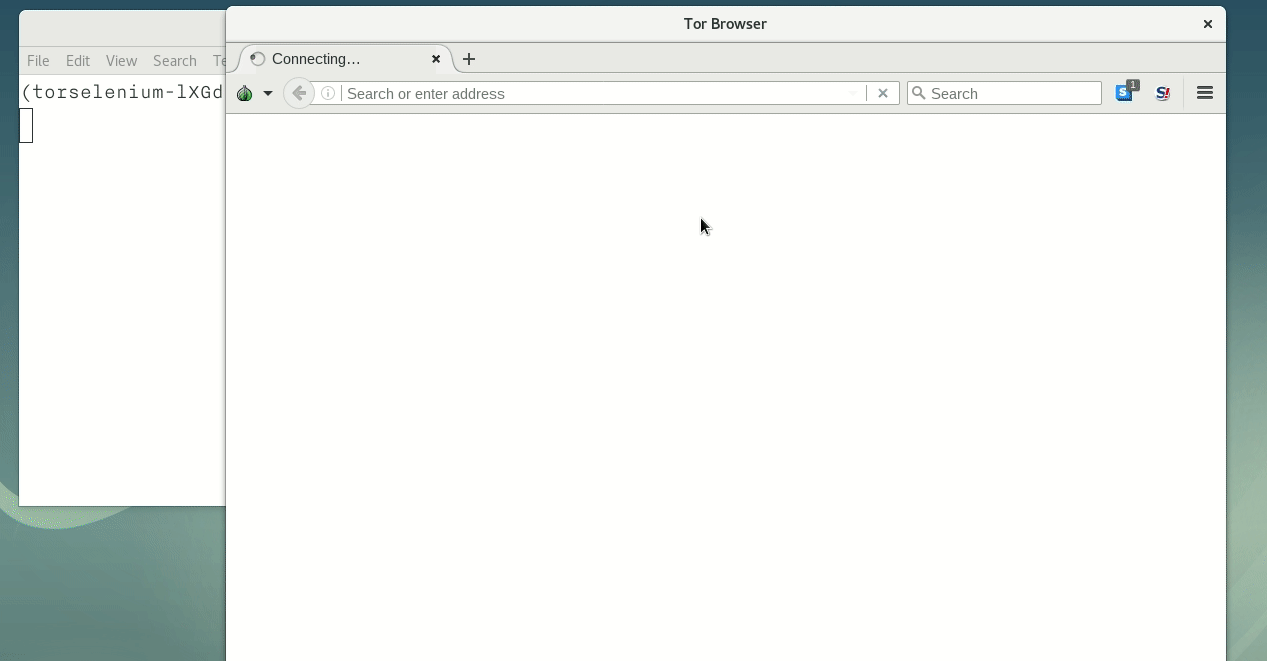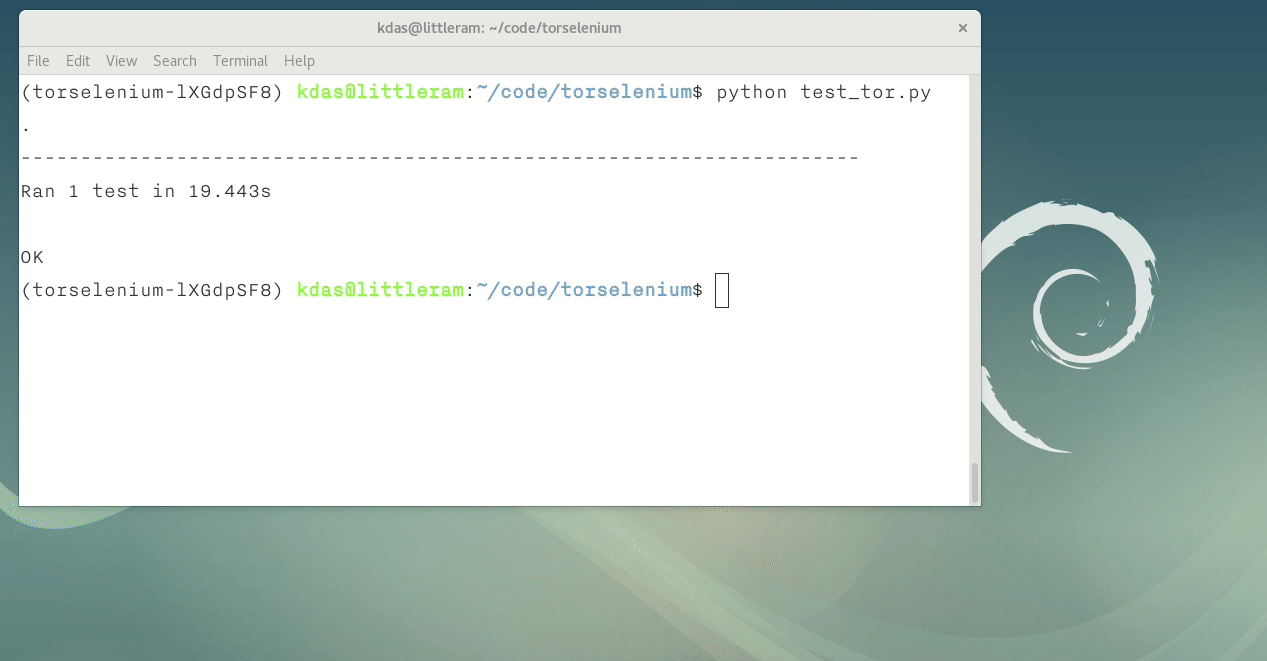
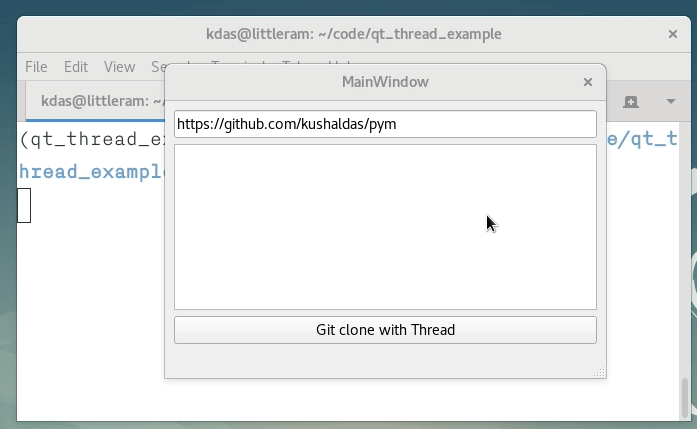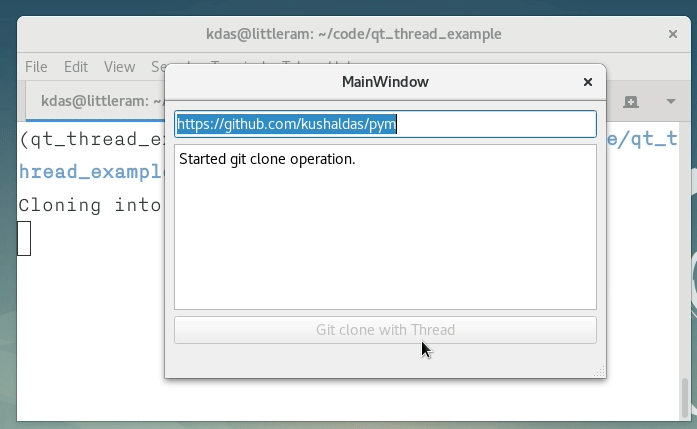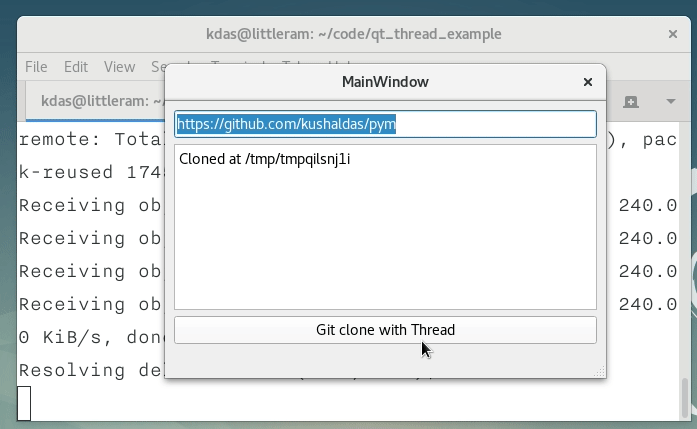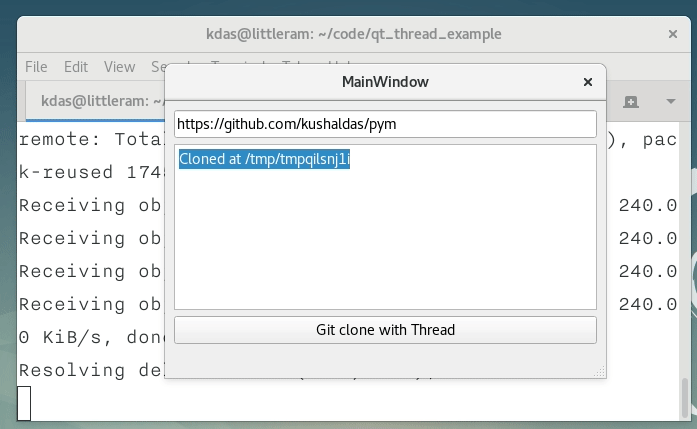
 May 24, 2018 10:14 AM
May 24, 2018 10:14 AM Example of Scratch code that uses a cloud variable to keep track of high-scores among all players of a game.
Example of Scratch code that uses a cloud variable to keep track of high-scores among all players of a game.
 Model-predicted probability that a project made by a prototypical Scratch user will contain data structures (w/o counting projects with cloud variables)
Model-predicted probability that a project made by a prototypical Scratch user will contain data structures (w/o counting projects with cloud variables)
 May 14, 2018 01:36 PM
May 14, 2018 01:36 PM





 April 30, 2018 08:33 PM
April 30, 2018 08:33 PM April 24, 2018 08:22 AM
April 24, 2018 08:22 AM
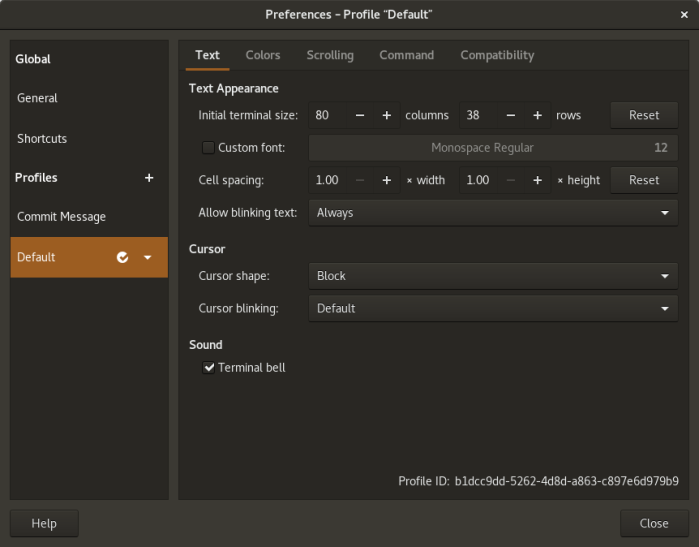
 u sign forms on wall writingsThe green mark indicates the usage of reformed orthography to write പു (pu), blue indicates the usage of exhaustive set orthography to write ക്കു (kku). But the one in red is an unusual usage of exhaustive orthography to write ത്തു (ththu). Such usages are commonplace now, mainly due to the lack of academic training as I see it.
u sign forms on wall writingsThe green mark indicates the usage of reformed orthography to write പു (pu), blue indicates the usage of exhaustive set orthography to write ക്കു (kku). But the one in red is an unusual usage of exhaustive orthography to write ത്തു (ththu). Such usages are commonplace now, mainly due to the lack of academic training as I see it. Redundant usage of vowel sign of u is indicated in circle
Redundant usage of vowel sign of u is indicated in circle As seen in the table, the signs ു, ൂ, ൃ ([u] ,[uː], [rɨ] ) changes the shape of the base consonant grapheme. It was not until the 1971 orthographic reformation these signs got detached from the base grapheme. You can see the detached form as well in the rows 5,6 and 7 of the above table.
As seen in the table, the signs ു, ൂ, ൃ ([u] ,[uː], [rɨ] ) changes the shape of the base consonant grapheme. It was not until the 1971 orthographic reformation these signs got detached from the base grapheme. You can see the detached form as well in the rows 5,6 and 7 of the above table.

 Excerpt from Alphabetum grandonico-malabaricum sive samscrudonicum describing the usage of ‘ു’ [u] and ‘ൂ’ [uː] signs
Excerpt from Alphabetum grandonico-malabaricum sive samscrudonicum describing the usage of ‘ു’ [u] and ‘ൂ’ [uː] signs Grammar of Malayalam- George Mathan
Grammar of Malayalam- George Mathan Grammar of Malayalam- George Mathan
Grammar of Malayalam- George Mathan











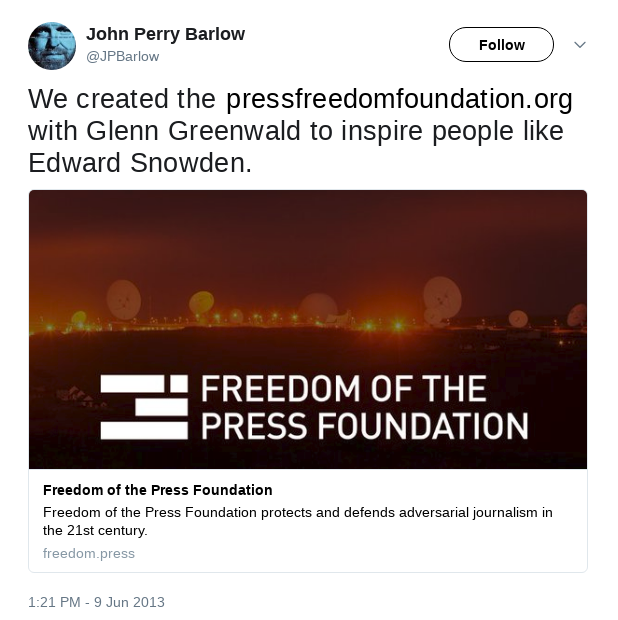






 Christmas Settings: https://xkcd.com/1620/
Christmas Settings: https://xkcd.com/1620/